My AWS Notebook
RDS: 20 GiB - 64 TiB of storage (except max 16 TiB for SQL Server), Interface: SQL
Availability, reliability, fault tolerance, upgrade
Multi-AZ: Automatic failover to standby (routing DNS entries), complete within 1 - 2 minutes. (Ref)
Single-AZ: Need manual point-in-time-restore; can take several hours to complete. (Ref)
Hardware maintenance (Ref)
Multi-AZ deployments are unavailable for the time it takes the instance to failover (1 - 2 min) if the AZ is affected by the maintenance. If only the secondary AZ is affected, then there is no failover or downtime.
Single-AZ deployments are unavailable for a few minutes.
Auto OS/system maintenance:
DB engine maintenance (optional auto minor version upgrade, manual major engine version upgrade):
A Read replica can be manually promoted to a standalone database instance.
RDS allows a standby instance in another Region. Combining this feature with Multi-AZ read replicas further improves availability, latency, and disaster recovery. Choose an instance class optimized for provisioned IOPS for consistent performance in the event of a failover to standby.
You can also promote a cross-region read replica to be the primary instance.
Put an SQS queue in front of the database. If the database is unreachable, messages are stored in a queue. When the database becomes available, messages in the queue are resubmitted.
Multi-AZ and automatic failover (optional) (multi-az) (RDS FAQs)
Synchronous physical replication to keep data on the standby in different AZ up-to-date with the primary.
Only the primary instance is active.
Use Provisioned IOPS with Multi-AZ instances for fast, predictable, and consistent throughput performance.
Automatic failover to standby (routing DNS entries), complete within 1 - 2 minutes.
System upgrades and DB Instance scaling are applied first on the standby, prior to automatic failover.
Failover time can be affected by whether large uncommitted transactions must be recovered; use smaller transactions, and adequately large instance types for best results.
After the failover, RDS automatically rebuilds a standby server in another AZ.
Single-AZ: Need manual point-in-time-restore; can take several hours to complete, and any data updates that occurred after the latest restorable time (last 5 mins) will not be available. (Ref)
Use RDS Event Notification to monitor failovers. (Ref).
If your application caches DNS values, setting TTL (time to live) to less than 30 secs is a good practice in case there is a failover, where the IP address might change and the cached value might no longer be in service.
You might experience connection issues after a failover if the subnet of the primary instance has different traffic-routing rules than the subnet of the standby instance. Be sure the subnets in your database subnet group have consistent routing rules.
For SQL Server, do not enable the following modes as they turn off transaction logging, which is required for Multi-AZ (Ref)
Multi-Region = cross-region read replicas
Scaling - Read (Ref) (read-replicas)
RDS creates a second DB instance using a snapshot of the source DB instance. It then uses the engines’ native asynchronous replication to update the read replica whenever there is a change to the source DB instance.
Max 5 read replicas. All read replicas are accessible and can be used for read scaling.
No backups configured by default.
Database engine version upgrade is independent from the source instance.
Read replicas need not use the same type of storage as their master DB Instances.
You can set up a read replica with its own standby instance in different AZ. This functionality complements the synchronous replication, automatic failure detection, and failover provided with Multi-AZ deployments.
A Read replica can be manually promoted to a standalone database instance.
Adding read replicas to the database will improve performance and horizontally scale the reads, but it will NOT improve the reliability and fault tolerance of the architecture.
CloudWatch ReplicaLag metric: 0 = replica has caught up to the source DB instance; -1 = replication not active
To distribute the read traffic to the RDS read replicas, use R53 weighted record sets (Weighted routing policy).
Within a R53 hosted zone, create individual record sets for each Read Replica Endpoint (or Reader Endpoint) associated with the read replicas and give them the same weight. Then, direct requests to the endpoint of the record set.
RDS does not support reader endpoint with automatic load balancing of read traffic. This feature is only available for Aurora.
NLB supports only IP addresses and instance IDs as target types (not RDS endpoints).
ALB supports only IP addresses, instance IDs and Lambda functions as target types (not RDS endpoints).
Second-tier read replica (Ref)
Supported (Aurora, RDS MySQL/MariaDB); not supported (RDS PostgreSQL/Oracle/SQL Server).
You can create a second-tier Read Replica from an existing first-tier Read Replica. By creating a second-tier Read Replica, you may be able to move some of the replication load from the master database instance to a first-tier Read Replica. (Ref)
A second-tier Read Replica may lag further behind the master because of additional replication latency.
Scalability, can be within an AZ, Cross-AZ, or Cross-Region.
Cross-region read replicas (RDS-FAQs, PostgreSQL, MySQL, SQL Server, Oracle)
RDS (except RDS SQL Server) supports cross-region read replicas (with network latency).
For optimal performance, your replica instance must be the same class (or above) and same storage type as the source instance. Replica instances not only replay similar write activity as the master, but also serve additional read workloads.
Automated backups can be taken in each region.
Each region can have a Multi-AZ deployment.
Database engine version upgrade is independent in each region.
If you have performance issue caused by increased read activity on your RDS MySQL deployed in Multi-AZ:
Read Replicas may not be the most performant solution. Read Replica performance is dependent on the instance size.
Deploy a ElastiCache cluster in front of the RDS DB instance. ElastiCache offers a better read performance solution (provides sub-millisecond response for read queries).
RDS MySQL allows you to add table indexes directly to Read replicas, without those indexes being present on the master.
Scaling - Storage (Ref)
With storage autoscaling enabled, RDS starts a storage modification when:
The additional storage is in increments of whichever of the following is greater:
Enable storage auto scaling with ModifyDBInstance (modify-db-instance) action.
If –max-allocated-storage (GB) is greater than –allocated-storage, storage auto scaling is turned on.
If –max-allocated-storage == –allocated-storage, storage auto scaling is turned off.
If you start a storage scaling operation at the same time that RDS starts an autoscaling operation, your storage modification takes precedence. The autoscaling operation is canceled.
Autoscaling cannot be used with magnetic storage.
Autoscaling does not occur if the maximum storage threshold would be exceeded by the storage increment.
Autoscaling cannot completely prevent storage-full situations for large data loads, because further storage modifications cannot be made until 6 hours after storage optimization has completed on the instance. If you perform a large data load, and autoscaling does not provide enough space, the database might remain in the storage-full state for several hours. This can harm the database.
When you clone an RDS DB instance, the storage autoscaling setting is not automatically inherited by the cloned instance. The new DB instance has the same amount of allocated storage as the original instance.
Autoscaling cannot be used with the following previous-generation instance classes that have less than 6 TiB of orderable storage: db.m3.large, db.m3.xlarge, and db.m3.2xlarge.
When performing an upgrade, an InsufficientDBInstanceCapacity error is
returned, and you are unable to modify the RDS instance:
Retry the request with a different database instance class.
Retry the request without specifying an explicit AZ.
To prevent accidental deletion of RDS databases, either
Set the deletion policy of the database resource to retain.
Enable termination protection on the CloudFormation stack (disabled by default) with any status except DELETE_IN_PROGRESS or DELETE_COMPLETE.
Deleting a RDS instance
A cluster-level snapshot should be in place before deleting an RDS instance.
When deleting an RDS instance using CLI, the following error is encountered:
An error occurred (InvalidParameterCombination) when calling the
DeleteDBInstance operation: FinalDBSnapshotIdentifier cannot
be specified when deleting a cluster instance.
Use the –skip-final-snapshot flag in the CLI delete command to skip the final snapshot.
When the source database is deleted, what happens to the read replicas? (Ref)
All read replicas are promoted.
For MariaDB, MySQL, and Oracle RDS instances, when the source database is deleted, read replicas in the same region and cross-region read replicas are promoted.
For RDS PostgreSQL instances, when the source database is deleted, read replicas in the same region are promoted, and cross-region read replicas are set to replication status “terminated”.
Stopping a RDS database
You can stop a DB instance for up to 7 days. After 7 days, the DB instance is automatically started. This is required to perform the maintenance updates.
You can stop and start a DB instance whether it is configured for a single-AZ or for Multi-AZ, for database engines that support Multi-AZ deployments.
You cannot stop a DB instance that has a read replica, or that is a read replica.
You cannot modify a stopped DB instance.
You cannot delete a DB parameter group or an option group that is associated with a stopped DB instance.
Encryption: If enabled, applies to underlying storage for DB clusters, automated backups, read replicas, and snapshots.
Enabling encryption for existing RDS and Aurora with minimal downtime (rds-encryption) (rds-encryption-kms)
Encrypting an existing DB Instance is not supported. Two options to encrypt an existing DB instance:
You can create a snapshot of your DB instance, and then create an encrypted copy of that snapshot. You can then restore a DB instance from the encrypted snapshots. (Ref)
You can create a new DB Instance with encryption enabled and migrate your data into it.
An AWS account has a different default CMK for each Region.
Once an encrypted DB instance is created, you cannot change the type of CMK used by that DB instance.
The primary DB instance and its read replicas in the same Region must be encrypted with the same CMK.
If the primary DB instance and read replica are in different Regions, you encrypt using the CMK for that Region.
You cannot have an encrypted read replica of an unencrypted DB instance or an unencrypted read replica of an encrypted DB instance.
You cannot restore an unencrypted backup or snapshot to an encrypted DB instance.
RDS has support for Transparent Data Encryption (TDE) for SQL Server and Oracle (enabled with option group). This encryption mode allows the server to automatically encrypt data before it is written to storage.
Automatic Backups
Backup retention period: 0 - 35 days. 0 = disable automated backup.
Disabling automatic backups for a DB instance deletes all existing automated backups for the instance.
Default backup retention period is 7 days if you create the DB instance using the console.
Default backup retention period is 1 day if you create the DB instance using the RDS API or the AWS CLI.
Multi-AZ: Automated backups are taken from standby (experience latency for a few mins for Multi-AZ).
Single-AZ: I/O activity is suspended on your primary during backup.
To retain backups longer than 35 days, implement a Lambda function to initiate the RDS snapshot. The Lambda function can be triggered on a schedule using CloudWatch Events Rule.
To retain backups in a different region, copy manual RDS DB snapshot to the secondary region.
RDS does not offer capability to copy automated backups (e.g. to S3).
RDS does not offer capability to configure RDS automated backups to store data in a different region.
Manual Snapshots
DB Snapshots are kept until you explicitly delete them.
You cannot share a snapshot that has been encrypted using the default KMS encryption key.
You cannot share encrypted snapshots as public.
You cannot share Oracle or Microsoft SQL Server snapshots that are encrypted using Transparent Data Encryption (TDE).
To copy an encrypted snapshot from one Region to another, you must specify the KMS key identifier of the destination Region. This is because KMS CMKs are specific to the Region that they are created in.
To share a manual DB snapshot with another AWS account (Ref)
Sharing a manual DB snapshot, whether encrypted or unencrypted, enables authorized AWS accounts to copy the snapshot.
Sharing an unencrypted manual DB snapshot enables authorized AWS accounts to directly restore a DB instance from the snapshot instead of taking a copy of it and restoring from that.
However, you cannot restore a DB instance from a shared encrypted DB snapshot. Instead, you can make a copy of the DB snapshot and restore the DB instance from the copy.
You must also share the KMS CMK that was used to encrypt the snapshot with any accounts that you want to be able to access the snapshot (by adding the other account to the KMS key policy).
Principal: ARN of the AWS account (root) that you are sharing to
Allow: kms:CreateGrant
You cannot share a DB snapshot that uses an option group with permanent or persistent options.
To share an automated DB snapshot, create a manual DB snapshot by copying the automated snapshot, and then share that copy. (Ref)
Neither automated backups nor DB Snapshots can be taken from your Read Replicas.
The database cloning feature is only available in Aurora, not RDS.
Restoring from a DB snapshot (Ref)
You cannot restore a DB instance from a shared encrypted DB snapshot. Instead, you can make a copy of the DB snapshot and restore the DB instance from the copy.
To restore a DB instance from a shared snapshot using the AWS CLI or API, the snapshot ARN must be used as the snapshot identifier.
You can specify the parameter group when you restore the DB instance.
When you restore a DB instance, the option group associated with the DB snapshot is associated with the restored DB instance after it is created.
When restoring a DB instance to a specific PIT (automatic backup) or from a manual snapshot, the default DB security group is applied to the new DB instance.
If you need custom DB security groups applied to your DB instance, you must apply them explicitly (modify-db-instance) after the DB instance is available. (Ref)
After a restore, if you experience consistent connection timeout errors in related logs following each refresh operation, it could be because you have the default security group associated with the restored.
The PIT restore and snapshot restore features of RDS require a crash-recoverable storage engine.
InnoDB is the only supported storage engine for RDS MySQL. (Ref)
InnoDB storage engine supports automated backups on RDS MySQL.
InnoDB instances can also be migrated to Aurora.
MyISAM instances cannot be migrated to Aurora. However MyISAM performs better than InnoDB if you require intense, full-text search capability.
Federated Storage Engine is not supported by RDS.
InnoDB and XtraDB are the supported storage engines for RDS MariaDB.
Recommend these limits because having large numbers of tables significantly increases database recovery time after a failover or database crash.
max 10000 tables if io1 or gp2 (>= 200 GiB);
max 1000 tables if magnetic or gp2 (<200 GiB)
If you need to create more tables than recommended, set the innodb_file_per_table parameter to 0.
When attempting a point-in-time restore (PITR), the RDS MySQL DB instance status becomes “incompatible-restore”:
Tune the most used and most expensive queries to see if that lowers the pressure on system resources.
Enable automatic backups and set the backup window to occur during the daily low in write IOPS.
If you have scaled the compute and/or storage capacity of the source DB Instance, you should also scale the Read Replicas, which should have as much or more compute and storage resources as their respective source DB Instances for replication to work effectively.
If your database workload requires more I/O than you have provisioned, recovery after a failover or database failure will be slow. To increase the I/O capacity of a DB instance:
Convert from standard storage to either gp2 or io2 / io1.
Migrate to a DB instance class with High I/O capacity.
If you convert to Provisioned IOPS storage, make sure you also use a DB instance class that is optimized for Provisioned IOPS.
If you are already using Provisioned IOPS storage, provision additional throughput capacity.
For best IOPS performance, allocate enough RAM so that your working set resides almost completely in memory
The working set is the data and indexes that are frequently in use on your instance. The more you use the DB instance, the more the working set will grow.
To tell if your working set is almost all in memory, check the ReadIOPS metric using CloudWatch while the DB instance is under load.
The value of ReadIOPS should be small and stable.
If scaling up the DB instance class (to a class with more RAM) results in a dramatic drop in ReadIOPS, your working set is not almost completely in memory.
Continue to scale up until ReadIOPS no longer drops dramatically after a scaling operation, or ReadIOPS is reduced to a very small amount.
RDS Proxy is a service that can be used to pool simultaneous connections from serverless applications and alleviate the connection management from the RDS database instance.
The best number of user connections for a DB instance will vary based on the instance class and the complexity of the operations being performed.
Investigate disk space consumption if space used is consistently at or above 85% of the total disk space. See if it is possible to delete data from the instance or archive data to a different system to free up space.
High CPU or RAM consumption might be appropriate, provided that they are in keeping with your goals for your application (like throughput or concurrency) and are expected.
To develop a cost-effective disaster recovery plan that will restore the database in a different Region within 2 hours (RTO), and the restored database should not be missing more than 8 hours of transactions (RPO). (4)
Backup-and-restore is the most cost-effective solution to provide a 2-hour RTO and 8-hour RPO.
Schedule a Lambda function to create an hourly snapshot of the DB instance, and another Lambda function to copy the snapshot to the second Region.
For disaster recovery, create a new RDS Multi-AZ DB instance from the last snapshot.
Failing to connect to a newly created database could be because:
The database instance state is not yet available.
The instance must have a public ip address.
The inbound rules on the instance Security Group are not configured properly.
If encountering a connection timed out error when attempting to query a RDS PostgreSQL DB using pgAdmin:
The corporate firewall is blocking access to port 5432. Update the DB and SG settings to use a different port.
The DB instance is not publicly accessible. Create an IGW for the subnets in the DB subnet group.
Max 40 RDS DB instances by default. (Max 10 for Oracle or SQL Server if under “License Included” model).
Unlimited number of databases and schemas can be run within a DB instance; except
RDS for SQL Server: max 100 databases per instance
RDS for Oracle: 1 database per instance; no limit on number of schemas per database imposed by software
Deprecated DB engine version
When a minor version of a DB engine is deprecated in RDS, at the end of a 3 month period after the announcement, all instances still running the deprecated minor version will be scheduled for automatic upgrade to the latest supported minor version during their scheduled maintenance windows.
When a major version of a DB engine is deprecated in RDS, at the end of a minimum 6 month period after the announcement, an automatic upgrade to the next major version will be applied to any instances still running the deprecated version during their scheduled maintenance windows.
Once a major or minor database engine version is no longer supported in RDS, any DB instance restored from a DB snapshot created with the unsupported version will automatically and immediately be upgraded to a currently supported version.
Hybrid or on-premises deployment options: RDS on Outposts and RDS on VMware.
A DB parameter group contains engine configuration values that are applied to one or more DB instances. (Ref)
To limit the no. of simultaneous connections that a user account can make on a RDS MySQL DB instance:
Create a new custom DB parameter group.
Modify the max_user_connections parameter to 10.
Update the RDS MySQL DB instance to use the new parameter group.
A DB cluster parameter group contains engine configuration values that are applied to all DB instances in a DB cluster.
The Aurora shared storage model requires that every DB instance in an Aurora cluster use the same setting for parameters such as innodb_file_per_table.
To enable audit logs of a Aurora MySQL DB cluster, including database events e.g. connections, disconnections, tables queried, or types of queries issued (DML, DDL, or DCL).
Create a DB cluster parameter group, and configure the Advanced Auditing parameters. And then associate the custom parameter group with the Aurora DB cluster.
Modify the log export configuration of the RDS cluster to publish logs to CloudWatch (log group).
A custom option group is used to enable and configure additional features provided by some DB engines. (Ref)
To enable MySQL (or MariaDB) audit logs using MARIADB_AUDIT_PLUGIN.
To perform SQL Server native backup using .bak files (SQL Server specific functionality).
You cannot modify the parameter settings of a default parameter group. Instead, you create your own custom parameter group where you choose your own parameter settings.
Not all DB engine parameters can be changed in a parameter group that you create.
Static parameters require a manual reboot of the RDS instance before they are applied.
Dynamic parameters do not require a manual reboot and are applied immediately regardless of the Apply Immediately setting.
You must reboot the instance for the changes to take effect, if you (Ref)
modify a DB instance,
change the DB parameter group associated with the instance, or
change a static DB parameter in a parameter group the instances use.
Troubleshooting
A RDS MySQL database instance is failing to reboot. Event logs show an error: “MySQL could not be started due to incompatible parameters”.
Compare the RDS DB instance DB parameter group to the default parameter.
Reset any custom parameters to their default value.
Reboot the instance.
Because one (or more) parameters are set to non-default values that are not compatible with the current RDS engine or instance class. To resolve the issue, you must reset the parameters to their default values.
You cannot modify the RDS instance that is in an incompatible parameter state. You must reset the values of the DB parameter group currently applied to the RDS instance.
RDS does not allow modification of MySQL system variables directly using the SET statement. Instead DB parameter groups must be used.
The time zone of a RDS MariaDB instance has been updated by setting the dynamic parameter time_zone in the DB parameter group to the local time zone of the application. But an application user is still reporting an incorrect time zone.
Ensure that the DB Parameter Group is applied to the RDS instance.
Instruct the application user to disconnect from the database and start a new session.
Dynamic parameters in DB parameter groups do not require RDS instance reboot.
rdsadmin.rdsadmin_util.alter_db_time_zone procedure is used to set the time zone of an Oracle DB instance.
MySQL / MariaDB
MySQL error log contains diagnostic messages generated by the database engine along with startup/shutdown times. Enabled by default. mysql-error.log is flushed every 5 mins; appended also to mysql-error-running.log.
MySQL audit log records database activity on the server for audit purposes, must be enabled using Option group with the MARIADB_AUDIT_PLUGIN option.
MySQL slow query and general logs must be enabled using DB Parameter groups (Ref):
general_log: contains a record of all SQL statements received from clients, and client connect and disconnect times. (0 or 1, default 0)
slow_query_log
long_query_time: To prevent fast-running queries from being logged in the slow query log, default 10s
log_queries_not_using_indexes
log_output (optional)
TABLE (default) to mysql.general_log table and mysql.slow_log table.
FILE to write both logs to the file system and publish them to CloudWatch Logs.
PostgreSQL
PostgreSQL error log contains connections/disconnections, checkpoints, autovacuum information and rds_admin actions in the error log.
PostgreSQL query log must be enabled using DB Parameter groups
Set the log_statement parameter to all.
Set the log_min_duration_statement parameter. Write to the postgres.log file when set to 1.
RDS Performance Insights displays DB load and the top SQL regardless of engine.
Performance Insights works best when the MySQL Performance Schema is enabled.
For Aurora PostgreSQL, DB load is subdivided by PostgreSQL 10 wait events.
For Aurora MySQL and RDS MySQL, DB load is subdivided by MySQL Performance Schema wait events.
RDS Event Notification can be enabled and provides notifications for various categories of database events. (Ref)
RDS uses SNS to provide a notification when an RDS event occurs.
These events can be configured for source categories: DB instance, DB security group, DB snapshot and DB parameter group. (NOT DB option group).
To set up a notification if the automatic backups are ever turned off, subscribe to RDS Event Notification and be sure to include the configuration change event “Automatic backups for this DB instance have been disabled”.
E.g. Configuration change event: “The master password for the DB instance has been reset”.
CloudWatch Application Insights for databases collects performance metrics and helps in troubleshooting by automatically correlating errors and creating visual dashboards. (Ref)
DynamoDB table
MySQL running on RDS, Aurora, or EC2
PostgreSQL running on RDS or EC2
Microsoft SQL Server running on RDS or EC2
Oracle running on RDS or EC2
You have a highly available production 10 TB SQL Server running on EC2. How to provide metrics visibility and notifications to troubleshoot performance and connectivity issues?
CloudWatch collects performance metrics of EC2 instances, not RDS instances. Further it collects host level metrics, and cannot identify issues relating to individual SQL queries.
Managed services (Aurora, DocumentDB, Neptune) use a distributed storage volume that is shared across the database instances. The auto-healing storage volume automatically replicates data 6 times across 3 AZs for durability and availability. The volume automatically scales with your dataset, up to 64 TiB.
See Image
Aurora Singe-Master Clusters (include provisioned, parallel query, global database, serverless)
Parallel Query is not compatible with Serverless and Backtrack features.
Backtracking is NOT supported with binary log replication (MySQL). Cross-region replication must be disabled before you can configure or use Backtracking.
MySQL vs. PostgreSQL
Features supports Aurora MySQL but not Aurora PostgreSQL (FAQs)
Multi-Master clusters
Parallel query
Backtrack
Read replica write forwarding feature in Aurora global database
Aurora MySQL Max table size (= Max Cluster Volume) = 128 TiB
Aurora PostgreSQL Max table size = 32 TiB
Interface: SQL
Availability, reliability, fault tolerance, upgrade
Aurora automatically promotes a Replica (in the same or different AZ) to become the new primary and flips the CNAME, complete within 30 seconds.
If there’s no replica (i.e. single instance), Aurora will attempt to create a new DB Instance in the same AZ on a best-effort basis and may not succeed, and will take longer time.
Global Database can promote a secondary region to take full read/write workloads in < 1 min (Ref).
Instance scaling will have an availability impact for a few minutes.
DB engine maintenance (optional auto minor version upgrade, manual major engine version upgrade). (Ref)
Database engine version upgrades are applied to all instances in a DB cluster at the same time.
An update requires a database restart on all instances in a DB cluster, (20 - 30 seconds of downtime), after which you can resume using your DB cluster.
Multi-AZ and automatic failover (optional)
When data is written to the primary DB instance, Aurora synchronously replicates the data across multiple AZs to 6 storage nodes associated with your cluster volume in a single Region, regardless of whether the instances in the DB cluster span multiple AZs.
When the primary DB instance becomes unavailable, Aurora automatically promotes a Replica (in the same or different AZ) to become the new primary and flips the CNAME, complete within 30 seconds.
You can specify the failover priority for Aurora Replicas.
Priorities range from 0 for the first priority to 15 for the last priority.
If more than one Aurora replicas have the same priority, RDS promotes the replica that is largest in size.
To ensure fast failover with Aurora PostgreSQL (Ref)
Use the provided read and write Aurora endpoints to establish a connection to the cluster.
Aggressively set TCP keepalives (e.g. 1s) to ensure that longer running queries that are waiting for a server response will be killed before the read timeout expires in the event of a failure.
Set the Java DNS caching timeouts aggressively (e.g. 1s) to ensure the Aurora read-only endpoint can properly cycle through read-only nodes on subsequent connection attempts.
Set the timeout variables used in the JDBC connection string as low as possible. Use separate connection objects for short and long running queries.
Use RDS APIs to test application response on server side failures and use a packet dropping tool to test application response for client-side failures.
Minimal application downtime during a failover
Enable Aurora DB cluster cache management.
Set a low value for the database and application client TCP keepalive parameters.
To initiate a failover for testing purpose from API (Ref)
FailOverDBCluster
ModifyDBInstance
DeleteDBInstance
The most operationally efficient approach for testing failover capabilities of a Aurora MySQL DB cluster in a single AZ.
Multi-region = cross-region read replicas (optional):
Physical replication: Aurora Global Database
Native logical replication: You can replicate to Aurora and non-Aurora databases, across regions (binlog for MySQL, and PostgreSQL replication slots for PostgreSQL)
Logical replication: Aurora MySQL also offers an easy-to-use logical cross-region read replica.
Aurora single-master cluster consists of: (UserGuide, FAQs)
One primary DB instance, supports read/write operations, performs all data modifications to the cluster volume.
One cluster volume, a SSD-backed virtual database storage volume that spans multiple AZs, with each AZ having a copy of the DB cluster data.
Max 15 Read Replicas, support only read operations, connect to the same storage volume as the primary DB instance. Maintain high availability by locating Aurora Read Replicas in separate AZs.
Endpoints of a Aurora cluster (Ref)
One cluster endpoint (or writer endpoint), connects to the current primary DB instance for the DB cluster.
Example endpoint: mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com:3306
The cluster endpoint can be used for read and write operations.
You use the cluster endpoint for all write operations on the DB cluster, including inserts, updates, deletes, and DDL (data definition language) and DML (data manipulation language) changes.
The cluster endpoint is the one that you connect to when you first set up a cluster or when your cluster only contains a single DB instance.
One reader endpoint provides automatic load-balancing support for read-only connections to the DB cluster.
Example endpoint: mydbcluster.cluster-ro-123456789012.us-east-1.rds.amazonaws.com:3306
If the cluster only contains a primary instance and no read replicas, the reader endpoint connects to the primary instance. In that case, you can perform write operations through the endpoint.
If the cluster contains one or more Replicas, the reader endpoint load-balances each connection request (not read requests) among the Replicas. In that case, you can only perform read-only statements such as SELECT in that session.
0 - 5 custom endpoints for an Aurora cluster represents a set of DB instances that you choose.
Example endpoint: myendpoint.cluster-custom-123456789012.us-east-1.rds.amazonaws.com:3306
When you connect to the endpoint, Aurora performs load balancing and chooses one of the instances in the group to handle the connection, based on criteria other than the read or read/write capability of the DB instances; e.g. based on instance class or DB parameter group
You cannot use custom endpoints for Aurora Serverless clusters.
Instance endpoint maps directly to a cluster instance
Scaling - Storage (Ref) (5 Scaling categories)
Aurora storage automatically scales with the data in your cluster volume, up to 128 TiB (tebibytes).
The storage space allocated to your Aurora database cluster dynamically decreases when you delete data from the cluster (since 2020-10).
For earlier versions without the dynamic resizing feature, resetting the storage usage for a cluster involved doing a logical dump and restoring to a new cluster. That operation can take a long time for a substantial volume of data. If you encounter this situation, consider upgrading your cluster to a version that supports volume shrinking.
When you clone an RDS DB instance, the storage autoscaling setting is not automatically inherited by the cloned instance. The new DB instance has the same amount of allocated storage as the original instance.
Scaling - Instance Scaling (Ref)
A change on DB Instance class will be applied during the specified maintenance window; use the “Apply Immediately” flag to apply your scaling requests immediately.
Instance scaling will have an availability impact for a few minutes as the scaling operation is performed.
Any other pending system changes will also be applied.
Aurora PostgreSQL does not support Multi-Master Cluster - i.e. can only have one master doing all writes. You will need to use vertical scaling (or instance scaling) approach for improving write operation when needed.
Scaling - Read Scaling
Max 15 read-only Aurora Replicas in a DB cluster that uses single-master replication.
Scaling for Write operations only supported by Aurora Multi-Master cluster.
Second-tier read replica (Ref)
Supported (Aurora, RDS MySQL/MariaDB); not supported (RDS PostgreSQL/Oracle/SQL Server).
You can create a second-tier Read Replica from an existing first-tier Read Replica. By creating a second-tier Read Replica, you may be able to move some of the replication load from the master database instance to a first-tier Read Replica.
A second-tier Read Replica may lag further behind the master because of additional replication latency introduced as transactions are replicated from the master to the first tier replica and then to the second-tier replica.
Scaling - Managing Connections
The maximum number of connections allowed is determined by the max_connections parameter in the instance-level parameter group for the DB instance.
The default value of that parameter varies depending on the DB instance class used for the DB instance and database engine compatibility.
Scaling - Managing Query Execution Plan.
Cross-region read replicas (Ref)
Asynchronous replication
All regions are accessible and can be used for reads.
Database engine version upgrades happen on all instances together.
Automated backups can be taken in each region.
Each region can have a Multi-AZ deployment.
Aurora allows promotion of a secondary region to be the master.
(1) Aurora Global Database (physical replication) (Ref)
Global Database clusters are single-master clusters providing subsecond replication across Regions.
Only the primary cluster performs write operations. Clients that perform write operations connect to the DB cluster endpoint of the primary cluster.
A secondary cluster does not have a writer primary DB instance. This functionality means that it can have up to 16 replica instances, instead of the limit of 15 for a single Aurora cluster.
Global Database can replicate to up to 5 secondary regions with typical latency < 1 sec.
Global Database can promote a secondary region to take full read/write workloads in < 1 min.
For low-latency global reads (not write) and disaster recovery.
Global Database uses a primary instance for write operations. Although there is automatic fail-over capacity, it is not without any downtime.
v3. Global Database’s write operations are issued directly to the primary DB instance in the primary Region. This does not reduce latency of write operations.
ix. Enable read replica write forwarding feature of Aurora MySQL (not PostgreSQL) (Ref)
1. You can reduce the number of endpoints that you need to
manage for applications running on your Aurora global
database, by using **write forwarding**.
2. Secondary clusters in an Aurora global database forward
SQL statements that perform write operations to the
primary cluster. The primary cluster updates the
source and then propagates resulting changes back to
all secondary Regions.
(2) Native logical replication to Aurora and non-Aurora databases, even across regions. (Ref)
PostgreSQL: PostgreSQL replication slots
MySQL: binlog (binary logging)
You can do replication (or cross-region replication) using binary log replication from/to Aurora MySQL, RDS MySQL, external SQL.
Enable binary logging on the replication source.
Retain binary logs on the replication source until no longer needed.
Create a snapshot of your replication source
However, if the replication source is Aurora DB cluster snapshot but the replica target is one of the follow:
an Aurora DB cluster owned by another AWS account,
an external MySQL database, or
an RDS MySQL DB instance,
Instead, create a dump of your Aurora DB cluster by connecting to your DB cluster using a MySQL client and issuing the mysqldump command.
Load the snapshot into your replica target
Enable replication on your replica target
Monitor your replica
Example: To replicate data in an Aurora MySQL database cluster to a RDS MySQL database instance in another Region: (3)
Enable binary logging on the development Aurora database. Retain binary logs until no longer needed.
Load the snapshot into the RDS MySQL instance by copying the output of the mysqldump command from your replication master (source).
(3) Aurora MySQL also offers an easy-to-use logical cross-region read replica (Ref)
Support up to 5 secondary Regions.
It is based on single threaded binlog replication, so the replication lag will be influenced by the change/apply rate and delays in network communication between the specific regions selected.
To enable binary logging (to replay changes on the cross-Region read replica DB cluster) (Ref)
Update the binlog_format parameter for the source Aurora DB cluster.
If your DB cluster uses the default DB cluster parameter group, create a new DB cluster parameter group to modify binlog_format settings.
We recommend that you set the binlog_format to MIXED. However, you can also set binlog_format to ROW or STATEMENT if you need a specific binlog format.
Reboot your Aurora DB cluster for the change to take effect.
Create a cross region read replica in the target region.
When you’re performing replication across Regions, ensure that your DB clusters and DB instances are publicly accessible. Aurora MySQL DB clusters must be part of a public subnet in your VPC. (Ref)
It is possible to set up replication where your Aurora MySQL database cluster is the replication master (MySQL feature), but this is not mandatory. It could also be set up as the replica.
When using Aurora MySQL to store transactional data, what can cause a replication failure? (Ref)
Binary logging on the primary database is not enabled.
The maximum allowed packets for the read replica does not equal the primary database maximum.
Deleting a Read Replica DB cluster
It is impossible to delete the last instance of a Read Replica DB cluster. A Read Replica cluster must be promoted to a standalone database cluster before it can be deleted.
Deletion protection on the source database does not affect deletion protection on read replicas.
You do not need to shut down a read replica in order to delete it.
Backtracking an Aurora DB cluster (support MySQL, not PostgreSQL) (Ref)
Backtrack rewinds a Aurora MySQL DB cluster to a specific time in minutes, without creating a new cluster.
The target backtrack window can go as far back as 72 hours.
The actual backtrack window is based on your workload and the storage available for storing information about database changes, called change records.
Aurora retains change records for the target backtrack window, and you pay an hourly rate for storing them.
You can enable the Backtrack feature when you create a new DB cluster or restore a snapshot of a DB cluster.
Backtracking causes a brief DB instance disruption. You must stop or pause your applications before starting a backtrack operation to ensure that there are no new read or write requests.
Backtracking is NOT supported with binary log (binlog) replication. Cross-region replication must be disabled before you can configure or use backtracking.
You can NOT use Backtrack with Aurora multi-master clusters.
A developer is doing some testing on an application using Aurora database. During the testing activities, the developer accidentally executes a DELETE statement without a WHERE clause. They wish to undo this action.
Use Aurora Backtracking feature, which enables one to revert an Aurora cluster to a specific point in time, without restoring data from a backup.
“Restore to point in time” feature, will launch a new cluster and restore it from backup data. Restoring from backup is a very time-consuming process that can take hours to complete. Further, this solution has costs associated with the additional Aurora cluster.
“Restore the Aurora database from a snapshot” does not restore data to a specific desired point in time. Additionally, restoring from a snapshot launches a new cluster, thus incurring additional costs. Since the restore happens from backup data, it can take hours to complete. Therefore, this is not the optimal solution.
Restore the Aurora from a read replica. - it is not possible to perform a restore from a read replica.
Database Cloning in an Aurora DB Cluster can quickly and cost-effectively create clones of all of the databases within an Aurora DB cluster. (Ref)
The clone databases require only minimal additional space when first created.
Database cloning uses a [copy-on-write protocol],
Initially, both the source database and the clone database point to the same pages. None of the pages has been physically copied, so no additional storage is required.
When the source database makes a change to the data (e.g. in page 1), instead of writing to the original page 1, a new page (e.g. page 1’) is created and the source database now points to the new page 1’. The clone database continues to point to Page 1.
When the clone database makes a change to the data (e.g. in page 4), instead of writing to the original page 4, a new page (e.g. page 4’) is created and the clone database now points to the new page 4’. The source database continues to point to Page 4.
You can make multiple clones from the same DB cluster.
You can also create additional clones from other clones.
You cannot create clone databases across AWS regions. The clone databases must be created in the same region as the source databases.
Max 15 clones based on a copy, including clones based on other clones. After that, only copies can be created. However, each copy can also have up to 15 clones.
You cannot clone from a cluster without the parallel query feature, to a cluster where parallel query is enabled.
You can provide a different VPC for your clone. But, the subnets in those VPCs must map to the same set of AZ.
When deleting a source database that has one or more clone databases associated with it, the clone databases are not affected. The clone databases continue to point to the pages that were previously owned by the source database.
Limitations of cross-account cloning:
The maximum number of cross-account clones that you can have for any Aurora cluster is 15.
You cannot clone an Aurora Serverless cluster across AWS accounts.
You cannot clone an Aurora global database cluster across AWS accounts.
Viewing and accepting sharing invitations requires using the AWS CLI the RDS API, or the AWS RAM console. Currently, you cannot perform this procedure using the RDS console.
When you make a cross-account cluster, you cannot make additional clones of that new cluster or share the cloned cluster with other AWS accounts.
Your cluster must be in ACTIVE state at the time that you share it with other AWS accounts.
While an Aurora cluster is shared with other AWS accounts, you cannot rename the cluster.
v3. You cannot create a cross-account clone of a cluster that is encrypted with the default RDS key.
ix. When an encrypted cluster is shared with you, you must encrypt the cloned cluster. The key you use can be different from the encryption key for the original cluster. The cluster owner must also grant you permission to access the KMS key for the original cluster.
Use cases
Experiment with and assess the impact of changes, such as schema changes or parameter group changes.
Perform workload-intensive operations, such as exporting data or running analytical queries.
Create a copy of a production DB cluster in a nonproduction environment for development or testing.
Encryption: optional
<.br>Enabling encryption for RDS and Aurora with minimal downtime
1. For an Aurora encrypted DB cluster, all DB instances, logs, backups,
and snapshots are encrypted.
2. You cannot disable encryption on an encrypted DB cluster.
3. You cannot create an encrypted snapshot of an unencrypted DB
cluster.
4. A snapshot of an encrypted DB cluster must be encrypted using the
same CMK as the DB cluster.
5. You cannot convert an unencrypted DB cluster to an encrypted one.
However, you can restore an **unencrypted snapshot** to an
encrypted Aurora DB cluster. To do this, specify a CMK when you
restore from the unencrypted snapshot.
6. You cannot unencrypt an encrypted DB cluster. However, you can
export data from an encrypted DB cluster and import the data into
an unencrypted DB cluster.
7. You cannot create an encrypted Aurora Replica from an unencrypted
Aurora DB cluster. You cannot create an unencrypted **Aurora
Replica** from an encrypted Aurora DB cluster.
8. KMS supports CloudTrail, so you can audit CMK usage to verify that
CMKs are being used appropriately.
1. If an instance status becomes inaccessible-encryption-credentials
1. The encryption key that the Aurora cluster uses may have been
disabled. The Aurora cluster is no longer available, and the
current state of the database cannot be recovered. The DBA
must re-enable the key and restore the cluster.
10. Manipulating the encrypted database snapshots
([Ref](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Overview.Encryption.html))
10. To copy an encrypted snapshot from one Region to another, you must
specify the CMK in the destination Region. This is because CMKs
are specific to the Region that they are created in.
11. The source snapshot remains encrypted throughout the copy process.
Aurora uses envelope encryption to protect data during the copy
process.
Backup and Restore
In the unlikely event your data is unavailable within Aurora storage, you can restore from a DB Snapshot or perform a PIT restore operation to a new instance.
Backup retention period: 1 - 35 days (always on)
Aurora always has automated backups enabled on DB Instances (which allows PIT restore).
Automated backups are taken from the shared storage layer.
The latest restorable time for a PIT restore operation (5 mins in the past).
Backups do not impact database performance.
There is no performance impact when taking snapshots.
It is not possible to perform a restore from a read replica.
Database Activity Streams (Aurora MySQL) provides a near real-time stream of database activities in your relational DB.
Solutions built on top of Database Activity Streams can protect your database from internal and external threats.
The collection, transmission, storage, and processing of database activity is managed outside your database, providing access control independent of your database users and admins.
Your database activity is asynchronously pushed to an encrypted Kinesis data stream provisioned on behalf of your Aurora cluster.
Performance tuning for Aurora
Design or integration with other AWS services
Aurora MySQL is used to store user data. A team would like to enhance the application by sending a welcome email every time a new user is created. They’ve implemented an Lambda function that will generate email text and send it using SES.
An Aurora MySQL has the message “Too many connections” in the error logs. How can it be resolved?
Use RDS proxy to establish a connection pool between the application and the database.
Scale the database up to an instance class with more memory.
Aurora Multi-Master cluster: cross multi-AZ, not multi-region (Ref)
Aurora Multi-Master cluster supports a maximum of 4 DB instances in a multi-master cluster.
The DB instances all have read/write capability and use the same AWS instance class.
Multi-master clusters don’t have a primary instance or read-only Aurora Replicas.
There isn’t any failover when a writer DB instance becomes unavailable, because another writer DB instance is immediately available to take over the work of the failed instance.
All the DB instances can write to the shared storage volume. For every data page you modify, Aurora automatically distributes several copies across multiple AZs.
In applications where zero downtime is required for database write operations, a multi-master cluster can be used to avoid an outage when a writer instance becomes unavailable..
All DB instances in a multi-master cluster must be in the same Region (not multi-region).
You cannot enable cross-Region replicas from multi-master clusters.
The Stop action isn’t available for multi-master clusters.
A multi-master cluster does not do any load balancing for connections. Your application must implement its own connection management logic to distribute read and write operations among multiple DB instance endpoints.
You cannot take a snapshot created on a single-master cluster and restore it on a multi-master cluster, or the opposite. Instead, to transfer all data from one kind of cluster to the other, use a logical dump produced by a tool such as AWS Database Migration Service (AWS DMS) or the mysqldump command.
You cannot use the parallel query, Aurora Serverless, or Global Database features on a multi-master cluster.
The Performance Insights feature isn’t available for multi-master clusters.
You cannot clone a multi-master cluster.
You cannot enable the backtrack feature for multi-master clusters.
Single AZ and automatic Multi-AZ failover (Best practices)
The DB instance for an Aurora Serverless DB cluster is created in a single AZ.
The storage volume for the cluster is spread across multiple AZs. The durability of the data remains unaffected even if outages affect the DB instance or the associated AZ.
Aurora Serverless clusters are monitored for availability and automatically replaced when problems are detected. Aurora Serverless manages the warmpool of pre-created DB clusters. The replacement process then fetches a new DB instance from the warmpooling service and replaces the unhealthy host.
Automatic Multi-AZ failover
In the unlikely event that an entire AZ becomes unavailable, Aurora Serverless launches a new instance for your cluster in one of the other AZs.
This failover mechanism takes longer for Aurora Serverless than for an Aurora provisioned cluster.
The Aurora Serverless AZ failover is done on a best effort basis because it depends on demand and capacity availability in other AZs within the given Region.
Because of that Aurora Serverless is not supported by the Aurora Multi-AZ SLA.
Scaling
Aurora Serverless uses a warm pool of servers to automatically scale capacity as a surge of activity is detected. It also scales back down automatically when the surge of activity is over.
If autoscaling times out with finding a scaling point, by default Aurora keeps the current capacity. You can choose to have Aurora force the change by enabling the Force the capacity change option.
Pause and resume DB cluster
You can choose to pause your Aurora Serverless DB cluster after a given amount of time with no activity. If enabled, default inactivity time is 5 minutes.
When the DB cluster is paused, no compute or memory activity occurs, and you are charged only for storage.
If database connections are requested when an Aurora Serverless DB cluster is paused, the DB cluster automatically resumes and services the connection requests.
When the DB cluster resumes activity, it has the same capacity as it had when Aurora paused the cluster. The number of ACUs depends on how much Aurora scaled the cluster up or down before pausing it.
If a DB cluster is paused for more than 7 days, the DB cluster might be backed up with a snapshot. In this case, Aurora restores the DB cluster from the snapshot when there is a request to connect to it.
DB cluster parameter group
Unlike provisioned Aurora DB clusters, an Aurora Serverless DB cluster has a single read/write DB instance that is configured with a DB cluster parameter group only.
does not have a separate DB parameter group.
During autoscaling, Aurora Serverless needs to be able to change parameters for the cluster to work best for the increased or decreased capacity.
Aurora Serverless PostgreSQL cannot use apg_plan_mgmt.capture_plan_baselines and other parameters that might be used on provisioned Aurora PostgreSQL DB clusters for query plan management.
Accessibility
An Aurora Serverless DB cluster cannot have a public IP address.
An Aurora Serverless DB cluster can be accessed from within a VPC or from a Data API HTTP endpoint.
To connect to a Serverless cluster from a database client (e.g. from a Cloud9 env) inside the same VPC (Ref):
Modify the cluster’s VPC security group to allow network traffic from your DB client to access the cluster.
Add a new Inbound Rule:
MySQL/Aurora (3306), TCP (6), Port range (3306), Source: SG of Cloud9 env
From Cloud9 env:
**mysql --user=(your Master username) --password -h (your
database endpoint)**
To connect to a Serverless cluster from a Lambda function, connect the Lambda function to the VPC via an ENI. (Ref)
When you connect a Lambda function to a VPC, Lambda creates an ENI for each combination of SG and subnet in your function’s VPC configuration.
Multiple functions connected to the same subnets share ENIs, so connecting additional functions to a subnet that already has a Lambda-managed network interface is much quicker. However, Lambda might create additional network interfaces if you have many functions or very busy functions.
If your function needs internet access, use NAT.
To integrate a SaaS product with an Aurora Serverless DB cluster, the simplest and most secure solution is to enable Data API on the Aurora Serverless cluster, to allow web-based applications to access the cluster over a secure HTTP endpoint. (Ref)
All calls to the Data API are synchronous. By default, a call times out if it’s not finished processing within 45 seconds. However, you can continue running a SQL statement if the call times out by using the continueAfterTimeout parameter.
Users don’t need to pass credentials with calls to the Data API, because the Data API uses database credentials stored in Secrets Manager.
To store credentials in Secrets Manager, users must be granted the appropriate permissions to use Secrets Manager, and also the Data API.
You can also use Data API to integrate Aurora Serverless with Lambda, AppSync, and Cloud9.
The API provides a more secure way to use Lambda. It enables you to access your DB cluster without you needing to configure a Lambda function to access resources in a VPC.
Logging
By default, error logs for Aurora Serverless are enabled and automatically uploaded to CloudWatch.
You can also have your Aurora Serverless DB cluster upload Aurora database-engine specific logs to CloudWatch by using a custom DB cluster parameter group.
Potential issue of Aurora Serverless cold start to APIG + Lambda (Ref)
Aurora Serverless Query Editor (in console) allows to run any valid SQL statement on the Aurora Serverless DB cluster, including data manipulation and data definition statements.
For Aurora Serverless, any enabled logging is automatically published to CloudWatch.
Limitations
Single AZ
Cannot use custom endpoints for Aurora Serverless clusters.
Cannot be used with Parallel Query.
A company would like to use a third-party vendor SaaS product to perform data analytics on data stored inside an Aurora Serverless cluster. What is the simplest, and most secure solution to integrate the SaaS product with the Aurora cluster?
Enable Data API on the Aurora Serverless cluster, to allow web-based applications to access the cluster over a secure HTTP endpoint.
NO: Create a VPC endpoint service inside the Aurora Serverless cluster’s VPC using AWS PrivateLink
NO: Create a VPC SG rule allowing inbound traffic from the SaaS product IP range. Apply the SG to the Aurora Serverless cluster’s VPC endpoint.
NO: Create a Site-to-site VPN connection from Amazon Aurora Serverless cluster’s VPC to the SaaS product vendor’s network.
Fully managed key-value database on SSDs (solid-state disks), delivers single-digit millisecond performance at any scale.
Max item size: 400 KB; Unlimited data volume; Interface: AWS API
Multi-AZ: Replicated in 3 AZs by default.
Multi-Region: DynamoDB Global Tables = Multi-Region Replication = Cross-Region Replication (Ref-1, Ref-2)
Global Tables automatically replicate data across 2 or more Regions, with full support for multi-master writes.
To create a global table
Enable DynamoDB Streams.
Ensure that this table is empty.
Ensure that a table with the same name does not exist in the selected Region.
Should also configure DynamoDB auto scaling for the global tables.
Capacity planning should account for additional write capacity associated with automatic multi-master replication.
Transactions are ACID-compliant only in the Region where the write is made originally.
Strongly consistent reads/writes vs. eventually consistent reads/writes
DynamoDB uses eventually consistent reads, unless you specify otherwise.
For Read operations (GetItem, Query, Scan) set ConsistentRead to true for strongly consistent reads.
Strongly consistent reads use more throughput capacity than eventually consistent reads.
Strongly consistent reads may have higher latency than eventually consistent reads.
Strongly consistent reads are not supported on GSI.
Read/Write Capacity Unit of Provisioned (= Read/Write Request Unit of On-demand) = (RCU, WCU below)
DynamoDB read and write speeds are determined by the number of available partitions.
A partition can support a maximum of 3000 RCUs, 1000 WCUs, 10GB of data.
For 5500 RCUs and 1500 WCUs: (5500/3000) + (1500/1000) = 3.333 -4 partitions
For 45 GB of data: (45/10) = 4.5 -5 partitions
Default Throughput (per table) Quotas: 40000 RCU, 40000 WCU
1 RCU provides 1 strongly consistent read, or 2 eventually consistent reads per second for item <= 4KB.
2 RCUs provide 1 transactional read per second for item <= 4 KB.
1 WCU provides 1 write per second for item <= 1KB.
2 WCUs provide 1 transactional write per second for item <= 1 KB.
Adding/updating/deleting an item in a table also costs a WCU and additional WCUs to write to any LSI and GSI.
E.g. 6 RCUs and 6 WCUs (Ref)
6 strongly consistent read x 4 KB = 24 KB per second
12 eventually consistent read x 4 KB = 48 KB per second
6 write x 1 KB = 6 KB per second
3 transactional read x 4 KB = 12 KB per second
3 transactional write x 1 KB = 3 KB per second
E.g. Item size 8 KB
2 RCUs for 1 strongly consistent read per second,
1 RCU for 1 eventually consistent read per second, or
4 RCUs for 1 transactional read per second.
E.g. Item size 10KB; for reading 80 strongly consistent items from a table per second.
How many RCUs in 10KB: 10KB / 4KB = 2.5 =3
Each item requires 3 RCUs; 80 items need: 3 * 80 = 240 RCUs. Strongly consistent reads
Eventually consistent reads =120 RCUs
On-Demand Capacity Mode (Ref-1)
Best solution for applications whose database workload is complex to forecast, with large spikes of short duration, or average table utilization well below the peak.
On-demand mode instantly accommodates up to double the previous peak traffic on a table.
However, throttling can occur if you exceed double your previous peak within 30 minutes.
Newly created table with on-demand capacity mode:
(Default) Previous peak = 6000 RCUs or 2000 WCUs
You can drive up to double the previous peak immediately, which enables newly created on-demand tables to serve up to 12000 RCUs or 4000 WCUs, or any linear combination of the two.
Existing table switched to on-demand capacity mode:
Provisioned Capacity Mode (Ref-1)
Best solution for predictable, consistent application traffic.
Burst Capacity: DynamoDB retains up to 5 mins of unused RCU/WCU capacity; but not guaranteed. (Ref)
DynamoDB Auto Scaling (Ref)
DynamoDB Auto Scaling uses Application Auto Scaling to dynamically adjust provisioned throughput capacity in response to actual traffic patterns.
This enables a table or a GSI to increase/decrease its provisioned read and write capacity to handle sudden change of traffic, without throttling. (Ref)
If you use the console to create a table or a GSI, DynamoDB auto scaling is enabled by default.
Scale without downtime but takes time. Decreases in throughput will take anywhere from a few seconds to a few minutes, while increases in throughput will take anywhere from a few minutes to a few hours.
The smallest amount of Reserved Capacity that one can buy: 100 RCU and 100 WCU
HTTP 400 (Bad Request) + ProvisionedThroughputExceededException: (Throttling exception)
Exceeding provisioned throughput limit (RCU/WCU per partition)
Might be trying to delete, create, or update tables too quickly.
Using one partition or key extensively.
Stale or unused data occupying partition and key space.
Your request rate is too high. The AWS SDKs for DynamoDB automatically retry requests that receive this exception. Your request is eventually successful, unless your retry queue is too large to finish. Reduce the frequency of requests and use exponential backoff.
HTTP 403
The request must contain either a valid (registered) AWS access key ID or X.509 certificate.
The X.509 certificate or AWS access key ID provided does not exist in our records.
The AWS access key ID needs a subscription for the service.
HTTP 500 (InternalFailure)
When network delays or network outages occur, strongly consistent reads on a DynamoDB table are more likely to fail and return a 500 error.
The request processing has failed because of an unknown error, exception or failure.
DynamoDB Streams
Manage Stream | View Type (cannot be changed after it’s created)
Keys only - only the key attributes of the modified item
New image - the entire item, as it appears after it was modified
Old image - the entire item, as it appeared before it was modified
New and old images - both the new and the old images of the item
Automatic Backup: optional; aka PITR (point-in-time recovery) (Ref)
Retention period: fixed 35 days when enabling PITR (point-in-time recovery)
The PITR process always restores to a new table, without consuming any provisioned throughput on the table.
Any number of users can execute up to 4 concurrent restores (any type of restore) in a given account.
You can do a full table restore using PITR, or you can configure the destination table settings on the restored table: GSIs, LSIs, Billing mode, Provisioned read and write capacity, Encryption settings.
A full table restore restores table data to that point in time, but all table settings for the restored table come from the current settings of the source table at the time of the restore.
You can restore your DynamoDB table data across Regions such that the restored table is created in a different Region from where the source table resides.
Restores can be faster and more cost-efficient if you exclude some or all indexes from being created on the restored table.
You must manually set the following on the restored table:
Auto scaling policies
Time to Live (TTL) settings
Point-in-time recovery settings
Stream settings
Tags
IAM policies
CloudWatch metrics and alarms
DynamoDB table export allows exporting data from any time within your PITR window to a S3 bucket.
On-demand Backup and Restore (Ref)
You can restore the table to the same Region or to a different Region from where the backup resides.
You can exclude secondary indexes from being created on the new restored table.
You cannot create new indexes at the time of restore.
You can specify a different encryption mode.
While a restore is in progress, don’t modify or delete your IAM role policy, to avoid any unexpected behavior.
If your backup is encrypted with an AWS managed CMK or a customer managed CMK, don’t disable or delete the key while a restore is in progress, or the restore will fail. After the restore operation is complete, you can change the encryption key for the restored table and disable or delete the old key.
DynamoDB does not have the deletion protection feature.
DynamoDB Time to Live (TTL) lets you define when items in a table expire so that they can be automatically deleted from the database. You can set the expiration date in epoch format in the TTL attribute on a per-item basis.
To limit storage usage to only those records that are relevant, or must be retained only for a certain amount of time (e.g. to enforce compliance and auditing requirements).
To ensure unauthorized updates to the TTL attribute are prevented,
When configuring DynamoDB table TTL, specify authorized users ARNs.
Use IAM policies to deny update actions to the TTL attribute or feature configuration. Create an IAM role policy that allows dynamodb:UpdateTimeToLive. Assign the role policy to the authorized users.
Enable DynamoDB Streams on the table for processing items deleted by TTL.
DAX (DynamoDB Accelerator)
DAX is a fully managed in-memory cache for read-heavy workloads with response times in microseconds for millions of requests per second; no need to manage cache invalidation, data population, or cluster management.
DAX only allows queries on the same partition key as the base table.
DAX is a DynamoDB specific caching solution and does NOT offer cross-region replication.
If the DAX node sizes are too small, you will receive ThrottlingException if the number of requests sent to DAX exceeds the capacity of a node.
DynamoDB transactions (Ref)
With the transaction write API, you can group multiple Put, Update, Delete, and ConditionCheck actions. You can then submit the actions as a single TransactWriteItems operation that either succeeds or fails as a unit.
You can group multiple Get actions and submit as a single TransactGetItems operation.
Enable automatic scaling on your tables, or ensure that you have provisioned enough throughput capacity to perform the 2 read or write operations for every item in your transaction.
Avoid using transactions for ingesting data in bulk. For bulk writes, it is better to use BatchWriteItem.
Each query can only use one index. If you want to query and match on two different columns, you need to create an index that can do that properly.
When you write your queries, you need to specify exactly which index should be used for each query.
GSI lets you query across the entire table to find any record that matches a particular value.
LSI can only help finding data within a single partition key.
Primary Keys and Secondary Indexes
Simple primary: Hash key = partition key, allowed data types: string, number, binary
Composite primary: Hash and range key = partition key and sort key
These keys are used for splitting the data across partitions.
Each partition is replicated across the 3 AZs automatically.
LSI (Local secondary index)
The primary key of a LSI must be composite (partition key and sort key).
Same partition key as the base table but a different sort key; same attributes
Support eventual consistency and strong consistency.
With a LSI, there is a limit on item collection sizes: For every distinct partition key value, the total sizes of all table and index items cannot exceed 10 GB.
Up to 5 LSI per table.
Can be created at the time of table creation; cannot be modified or deleted.
LSIs count against the provisioned throughput (performance) of the DynamoDB table.
GSI (Global secondary index)
The primary key of a GSI can be either simple (partition key) or composite (partition key and sort key).
Can use a different partition key (and different sort key if present) from those from the base table.
Like adding another DynamoDB table which gets changes propagated from the base table.
GSI supports eventually consistent reads; cannot do strongly consistent reads.
Default max 20 GSI per table. No size restrictions.
Can be added to existing tables.
Consistency lags behind the base table.
v3. Limit the projected attributes.
ix. GSIs have their own provisioned throughput independent of the main table.
x. If GSIs run out of provisioned throughput, the main table will be throttled, not just the GSIs.
If you want to create more than one table with secondary indexes, you must do so sequentially. For example, you would create the first table and wait for it to become ACTIVE, create the next table and wait for it to become ACTIVE, and so on.
Encryption-at-rest is always on and cannot be disabled.
Tables can be encrypted under
an AWS owned CMK (default; AWS/DynamoDB service default CMK),
an AWS managed CMK for DynamoDB in your account.
NOT support Customer managed CMKs.
The CMK is used to create a data key (table key) unique to each table. The table key is managed by DynamoDB and stored with the table in an encrypted form.
DynamoDB encrypts every item with a data encrypted key. The data encrypted key is encrypted with the table key and stored with the data.
Table keys are cached for up to 12 hours in plaintext by DynamoDB, but a request is sent to KMS after 5 minutes of table key inactivity to check for permission changes.
CloudTrail logs can be used to audit KMS CMKs (Customer Master Keys) and identify DynamoDB tables that are using the keys for encryption at rest.
Encryption-in-transit using dynamodb encryption client libraries
IAM can restrict which tables/streams a user can access, and which ITEMS and Attributes a user can access.
Logging and Monitoring
When CloudWatch Contributor Insights is enabled on a table or GSI, DynamoDB creates the following rules on your behalf: Most accessed items, Most throttled keys. (Ref)
CloudWatch metrics
ConsumedReadCapacityUnits - RCUs per time period used
ConsumedWriteCapacityUnits - WCUs per time period used
ReadThrottleEvents - Provisioned RCU threshold breached
WriteThrottleEvents - Provisioned WCU threshold breached
ThrottledRequests - ReadThrottleEvents + WriteThrottleEvents
DynamoDB updates the Storage Size value approximately only every 6 hours.
DynamoDB updates the ItemCount value approximately every 6 hours.
PutItem, UpdateItem, and DeleteItem have a ReturnValues parameter, which you can use to return the attributes before or after they are modified.
Attributes can be scalars, JSON, XML
Projection Type
KEYS_ONLY - Only the index and primary keys are projected (smallest index - more performant)
INCLUDE - Only the specified attributes are projected.
ALL - All attributes are projected (biggest index - least performant).
Data plane operations such as reads and writes to a table often have higher availability design goals than control plane operations such as changing the table metadata.
Best Practices (Ref)
get-item retrieves an item by its primary key. GetItem is highly efficient as it provides direct access to the physical location of the item.
Use get-item with Project expression to reduce the size of the read operations and increase read efficiency.
If a scan operation on a large DynamoDB table is taking a long time to execute, Parallel Scans can be used to decrease the execution time of the scan operation.
Conditional expressions allow a condition to be checked before an update-item is applied.
Store metadata in DynamoDB and blobs in S3.
For storing time series data, use a table per day, week, month etc.
If we put all the time series data in one big table, the last partition is the one that gets all the read and write activity, limiting the throughput.
If we create a new table for each period, we can maximize the RCU and WCU efficiency against a smaller number of partitions.
Recommended approach to store date for querying data in a DynamoDB table by date range: (Ref-1, Ref-2)
To locate all items in a DynamoDB table with a particular sort key
Scan against a table, with filters. But it is inefficient.
Query with a GSI. GSIs will allow a new index with the sort key as a partition key, and query will work.
LSIs can’t be used, they only allow an alternative sort key and query can only work against 1 partition key, with a single or range of sort.
GetItem won’t work, it needs a single Partition-Key and Sort-Key.
To truncate a DynamoDB table,
Use aws dynamodb scan to scan the table, iterate through all keys and use aws dynamodb delete-item to delete each item.
To delete multiple items, use the batch-write-item instead of delete-item.
Note that both scan operation and batch-write-item operations consume RCUs and WCUs.
If there are no requirements to keep the table, a faster and more cost-effective approach would be to delete and recreate the entire DynamoDB table.
To maintain a record of all GetItem and PutItem operations performed on a DynamoDB table for audit purposes.
DynamoDB data-plane API operations (e.g. GetItem, PutItem) are not logged into CloudTrail logs.
Enable DynamoDB Streams; DynamoDB streams record events every time any table item is modified. Use Lambda function to read, process and record these stream records.
To increase the speed of read operations:
Secondary Indexes, which contain a subset of attributes from a table, and an alternate key for queries
DAX, which works as an in-memory cache in front of DynamoDB.
What are some effective ways to handle extreme write burstyness on a table (e.g. black friday/xmas sales)
What are some effective ways to handle extreme read burstyness on a table (e.g. black friday/xmas sales)
Set an appropriate RCU on the table for nominal load and then utilise ElastiCache, S3, lambda to generate static content to offload DB read loads.
Utilise the burst capacity of a table, sparingly, which provides enough capacity to remove any peaks in demand.
What is the optimal method for importing a CSV file from S3 into the DynamoDB table? (Ref)
Use Lambda Function to read the file and import the data into the DynamoDB table (the simplest and most cost-efficient method).
AWS CLI can only import JSON formatted data into DynamoDB tables.
AWS Management Console only allows entering single items into DynamoDB tables.
Data Pipeline is not the optimal solution. It requires non-trivial activities and costs associated with configuration of Data Pipelines and EMR cluster infrastructure.
If after recreating a DynamoDB table with new LSI, the application starts to experience throttling when performing write operations on the base table even though the number of table updates has not increased, it could be because:
A DynamoDB table is currently configured for provisioned capacity mode. The company has just introduced a popular line of products. This is generating large volumes of data, with traffic peaking at over 4,000 reads per second. Reports are coming in that the application is slow and is occasionally returning outdated data. (3)
A partition can support a maximum of 3000 RCUs, 1000 WCUs, 10GB of data.
A partition is automatically split, creating two new partitions. The current throughput of the original partition is divided among the new partitions. This can lead to throttling if the throughput is insufficient.
The partition key is no longer effective and is resulting in hot partitions.
Using Web Identity Federation (WIF) (Ref)
If you are writing an application targeted at large numbers of users, you can optionally use Web Identity Federation for authentication and authorization.
The app calls a third-party identity provider (e.g. Amazon, Facebook, Google) to authenticate the user and the app. The identity provider returns a web identity token to the app.
The app calls AWS STS (Security Token Service) and passes the web identity token as input. AWS STS authorizes the app and gives it temporary AWS access credentials.
The app is allowed to assume an IAM role (e.g. GameRole) and access AWS resources in accordance with the role’s security policy.
The Condition clause determines which items in the GameScores table are visible to the app. It does this by comparing the Login (e.g. Amazon ID) to the UserId partition key values in GameScores.
Only the items belonging to the current user can be processed using one of DynamoDB actions that are listed in this policy. Other items in the table cannot be accessed.
Furthermore, only the specific attributes listed in the policy can be accessed. (Ref)
“Statement”: { “Sid”: “AllowAccessToOnlyItemsMatchingUserID”,
“Effect”: “Allow”,
“Action”: (
“dynamodb:GetItem”,
“dynamodb:Query”,
“dynamodb:PutItem”,
“dynamodb:UpdateItem”
),
“Resource”: ( “arn:aws:dynamodb:us-west-2:123456789012:table/GameScores” ),
“Condition”: {
“ForAllValues:StringEquals”: {
“dynamodb:LeadingKeys”: (
”${www.amazon.com:user_id}”
),
“dynamodb:Attributes”: ( “UserId”, “GameTitle”, “Wins”, “Losses” )
},
“StringEqualsIfExists”: {
“dynamodb:Select”: “SPECIFIC_ATTRIBUTES”
}
}
}
)
For a relational database deployed to EBS-backed EC2 instance
RAID 0 is used to distribute I/O across volumes and achieve increased IOPS and throughput performance. (Ref)
RAID 1 is used to simultaneously write data to multiple volumes thus providing increased data redundancy.
AWS does not recommend RAID 5 and RAID 6 for EBS volumes.
A database being migrated to EC2 instances requires 10000 IOPS. Which EBS Volume type should be used?
gp2 / gp3 volume type provides max 16,000 IOPS
io2 (max 256,000 IOPS), io1 (max 64,000 IOPS), st1 (max 500 IOPS), sc1 (max 250 IOPS)
Instances
Memory optimized (R5) - memory-intensive apps, high performance DB, distributed in-memory caches
Storage optimized (I3) - high-volume IOPS requiring low-latency, internet-scale non-relational databases
Burstable performance (T3) - consistent cost for unpredictable workloads, smaller DB with spiky usage
Storage
Provisioned IOPS SSD - I/O apps needing consistent low latency, large databases
General purpose SSD - default type, small to medium sized DB, dev/test env, boot volumes
Magnetic volumes - least expensive EBS volume type, infrequent data access
DMS is a tool that performs data migration during a database migration process.
ME: When using DMS to replicate RDS from account 1 region A to Redshift in account 2 region B, should the replication instance in account 1 or 2, region A or B?
DMS can be used for continuous data replication with high availability.
The source database remains fully operational during the migration.
Sources -DMS (Task on replication instance (EC2)) -> Targets (Ref)
Either the source or the target database (or both) need to reside in RDS or on EC2 (i.e. not on-prem to on-prem).
If the replication instance is in a storage-full state, the migration tasks may fail without an error message.
On-prem/EC2 instance databases
Azure SQL Database (support full data load, not support Change data capture (CDC))
RDS, DocumentDB, S3 (support full data load and change data capture (CDC) when using S3 as a source)
On-prem/EC2 instance databases
RDS, S3, DynamoDB, Redshift, Elasticsearch Service, Kinesis Data Streams, MSK, self-managed Kafka, DocumentDB, Neptune
DMS does not support cross-region migration for the following target endpoint types:
SCT is a tool for accessing schema conversion and converting existing database schema from one database engine to another.
DMS vs. SCT
DMS traditionally moves smaller relational workloads (<10 TB) and MongoDB, whereas SCT is primarily used to migrate large data warehouse workloads.
DMS supports ongoing replication to keep the target in sync with the source; SCT does not.
WQF (Workload Qualification Framework) with SCT
WQF is a standalone tool that is used during the database migration planning phase to assess migration workloads. It produces an assessment report detailing migration complexity and size, and provides migration strategy and tool recommendations. (Ref)
Classify OLTP and OLAP workloads using SCT with WQF
You can use WQF for the following migration scenarios: (Ref)
Oracle to RDS PostgreSQL or Aurora PostgreSQL
Oracle to RDS MySQL or Aurora MySQL
SQL Server to RDS PostgreSQL or Aurora PostgreSQL
SQL Server to RDS MySQL or Aurora MySQL
DataSync is a data migration service for transferring data from on-premise file storage sources to AWS services such as S3 and EFS
Conversion of stored procedures
SCT automates the conversion of Oracle PL/SQL and SQL Server T-SQL code to equivalent code in the Aurora / MySQL dialect of SQL or the equivalent PL/pgSQL code in PostgreSQL.
When a code fragment cannot be automatically converted to the target language, SCT will clearly document all locations that require manual input from the application developer.
DMS can be used with Snowball Edge and S3 to migrate large databases. (Ref)
You use the SCT to extract the data locally and move it to an Edge device.
You ship the Edge device or devices back to AWS.
After AWS receives your shipment, the Edge device automatically loads its data into a S3 bucket.
DMS takes the files and migrates the data to the target data store. If you are using change data capture (CDC), those updates are written to the S3 bucket and then applied to the target data store.
A DMS replication instance had unintentionally been configured to be publicly accessible. Access to the DMS replication instances should only be available to a host within the same VPC. To fix the issue, either:
Change the subnets associated with the replication instance from public to private, OR
Delete the replication instance and all tasks using it before recreating it.
Migration
Physical migration means that physical copies of database files are used to migrate the database.
Logical migration means that the migration is accomplished by applying logical database changes, such as inserts, updates, and deletes.
Migrate from Aurora to Aurora Serverless and vice versa (Ref)
Migrate from RDS to Aurora MySQL (Source)
Migrate from a RDS MySQL DB Snapshot to an Aurora MySQL DB cluster. (Source)
Migrate from a RDS MySQL DB instance by creating an Aurora MySQL Read Replica. (Source)
Migrate from RDS to Aurora PostgreSQL (Source)
Migrate from a RDS PostgreSQL DB Snapshot to an Aurora PostgreSQL DB cluster (Source)
Migrate from a RDS PostgreSQL DB instance by creating an Aurora PostgreSQL Read Replica. (Source)
Import data from S3 into a table belonging to an Aurora PostgreSQL DB cluster using the aws_s3.table_import_from_s3 function. (Source)
Migrate from external MySQL database to Aurora MySQL
Only if your database supports the InnoDB or MyISAM tablespaces.
If the external MySQL database uses memcached, remove memcached before migrating it.
Option 1: Use mysqldump utility to create a dump of your data, then import data into an existing Aurora MySQL DB cluster. mysqldump utility uses DDL and DML statements to recreate the database schemas and load the data, it is a very time consuming process.
Option 2: Use xtracbackup (Percona XtraBackup utility) to create backup files from the source database to a S3 bucket, and then restore an Aurora MySQL DB cluster from those files using the “Restore from S3” option (considerably faster than using mysqldump).
Option 3: Save data from your database as text files and copy those files to an S3 bucket. Then load that data into an existing Aurora MySQL DB cluster using the LOAD DATA FROM S3 MySQL command.
To plan a database conversion and migration from on-premise database cluster to AWS, a database migration assessment report shall be created to assess the migration compatibility, task, effort, and recommendations.
Install the SCT Tool on a virtual machine with access to on-prem network.
Install database drivers required to connect to the source and target database.
Migrate from a EC2-based MySQL database to RDS MySQL database
How to perform data validations on the target database with the most operational efficiency?
The database is fairly large in size and has an uptime requirement near 24X7. There are a significant number of tables in the MySQL database that cannot be migrated due to company regulations. Requirements: rapid implementation and minimal downtime. (3)
Create a new RDS MySQL database. Use the DMS table mapping function to ensure that only the specified tables are migrated. Ensure that the migration is performed in change data capture (CDC) mode.
Should not use Read replica - Read replica copies all tables, so confidential information would be copied.
Should not use Snapshot - Snapshots extract all tables and increase downtime.
mysqldump can dump some tables when used with –ignore-table, but the downtime would be longer.
Migrate from Cassandra cluster to DynamoDB
Install SCT Data Extraction Agent. SCT data extraction agents are required when the source and target databases are significantly different and require complex data transformations.
Create a Clone Datacenter. The extraction process performed by the data extraction agents imposes additional overhead load on the Cassandra database. In order to avoid having a negative impact on the operation and performance of the source production cluster, a clone datacenter containing a copy of the production data should be created. SCT should be configured to connect to this clone cluster.
Create an S3 bucket. S3 bucket is required to store the output of the data extraction agent conversion and migration process.
Migrate from MongoDB cluster to DocumentDB
To perform an online data migration from on-premise MongoDB cluster to DocumentDB in order to minimize source database downtime, DMS is being used to perform data migration. Before beginning the full load of migration data (Ref)
Create indexes on the target database. Because DMS does not migrate indexes. For large data migrations, it is most efficient to pre-create indexes in the target DocumentDB cluster before migrating the data.
Recommend to use DMS on the secondary node of source cluster (replica set) for the read operations as it can result in reducing the overall load on the primary instance.
Turn on CDC (change data capture) on the source database. CDC is required in online data migration. DMS uses CDC to replicate changes to target DocumentDB.
DMS uses the source MongoDB oplog to perform data migration. During an online data migration, the oplog on each replica set should be large enough to contain all changes made during the entire duration of the data migration process.
To move a 15TB MongoDB database to a DocumentDB and should be fast and incur minimum downtime: (3)
Migrate the database with a hybrid approach, using the mongodump and mongorestore tools for an initial full load and DMS with change data capture (CDC) to replicate changes.
(The hybrid approach balances migration speed and downtime).
Migrate the database with an online approach, using DMS with a full load and CDC strategy (minimum downtime but slow)
Migrate the database with an offline approach, using DMS with a full load strategy (fast migration but long downtime)
Migrate from SQL based database to DynamoDB
To refactor and migrate an application from using a relational SQL based database to a NoSQL DynamoDB database, what is the first action should do when designing the application data model for DynamoDB?
Migrate from a RDS Oracle to Aurora MySQL
Create the target database.
Run the conversion report using SCT and execute generated scripts.
Resolve any issues from the SCT stage.
Disable foreign keys and perform a full load migration using DMS.
Enable foreign keys and other constraints that may have been disabled during the migration
Migrate from Oracle database to Aurora PostgreSQL
During the planning phase, the solution architect would like to perform an assessment of migration complexity and size, and identify any proprietary technology that would require database and application modifications. What service can help the solution architect with developing this assessment report and provide recommendations on migration strategies and tools?
Migrate from an on-premise enterprise Oracle database to EC2 instances
To migrate an on-premise enterprise Oracle Database that utilizes Oracle Data Guard for data replication.
Implement Oracle Database cluster on EC2 instances. Because to utilize Oracle Database Enterprise features on AWS, EC2 instances must be used for implementation.
RDS Option Groups do not support Oracle Data Guard as an option for Oracle RDS databases.
RDS Multi-AZ uses different technology than the high-availability technology provided by Oracle Data Guard.
To migrate an enterprise Oracle database to local SSD-backed EC2 instances requiring high random I/O performance and high IOPS.
i-family EC2 instance type provides SSD-backed instance storage optimized for low latency, high random I/O performance, and high IOPS performance.
If an instance type supports both EBS backed and local NVMe-based SSD storage, a quick method to identify if it is an SSD backed EC2 type is to check if the identifier has a “d” in its name (e.g. “c5” vs “c5d”).
Migrate from an on-premise enterprise Microsoft SQL Server to EC2 instances. Current on-premise configuration utilizes SQL Server Reporting Services (SSRS).
Install Microsoft SQL Server on EC2 instances.
SQL Server Reporting Services is not available on RDS instances. If this service and feature is required in AWS cloud, the only viable option is to install Microsoft SQL Server database on EC2 instances. Therefore, option C is CORRECT and all other options are incorrect. (Ref)
(NEW): RDS for SQL Server now supports SQL Server Reporting Services (SSRS)
Migrate from Informix to Aurora
Manually create the target schema on Aurora then use Data Pipeline with JDBC to move the data.
Informix is not supported by either the DMS or SCT so the only choice among these options is manually creating the schema.
Memcached vs. Redis (Ref)
Caching Strategies (Ref-Memcached, Ref-Redis, Image)
A cache hit occurs when data is in the cache and isn’t expired.
A cache miss occurs when data isn’t in the cache or is expired.
Lazy loading caching strategy loads data into the cache only when it is requested by the application. Thus, it reduces use of cache space by items not frequently requested.
Use case: The application frequently requests the same items. The team wants to minimize cache space utilization and infrastructure costs.
However, it updates data in cache only when a cache miss occurs. This means that the cache can contain stale data that is out of date with the data stored in the source database.
Write-Through caching strategy updates the cache with every write operation thus ensuring that the cache always contains the most recent data.
It is related to the consistency of data in cache in relation to the base source database.
Use case: The application has a requirement that the data must always be the most recent.
A node is a fixed-size chunk of network-attached RAM. It is the smallest building block of an ElastiCache deployment and can run an instance of Memcached or Redis.
Reserved memory
Memcached uses a metric called SwapUsage and if SwapUsage exceeds 50 MB, you need to increase the memcached_connections_overhead parameter.
Redis does not use SwapUsage but instead, uses the reserved-memory metric.
In ElastiCache, if a primary or read replica cluster is unexpectedly terminated or fails, replication groups guard against potential data loss because your data is duplicated over two or more clusters. For greater reliability and faster recovery,
create one or more read replicas in different AZs for your replication group, and
enable Multi-AZ with auto failover on the replication group instead of using Append only files (AOF).
To connect to a Memcached or Redis node, you must first connect to the EC2 instance using the connection utility of your choice, and then use the telnet command (Memcached) or redis-cli (Redis) to connect to the node or cluster and then run database commands like “set a 0 0 5” (Memcached) or “set a “hello” (Redis).
To delete a ElastiCache cluster with the CLI, you can use the delete-cache-cluster operation.
ElastiCache provides both host-level metrics (e.g. CPU usage) and metrics that are specific to the cache engine software (e.g., cache gets, cache misses) in 60-second intervals.
Max 155 TiB, Interface: Memcached API, Port: 11211
1-20 nodes per cluster (soft limit), 100 nodes per Region (soft limit)
Availability
Memcached does not support replication, so a node failure will always result in some data loss from your cluster.
However, if you partition your data, using a greater number of partitions means you’ll lose less data if a node fails.
Also, to mitigate the impact of an AZ failure, locate your nodes in as many AZs as possible.
NOT supported: automatic failover, backup, encryption, Global Datastore, replication
Scaling cluster horizontally (add/remove nodes to/from a cluster; 1-20 nodes per cluster) (Ref):
Changing the number of nodes in a Memcached cluster changes the number of the cluster’s partitions.
Some of your key spaces need to be remapped so that they are mapped to the correct node.
Remapping key spaces temporarily increases the number of cache misses on the cluster.
If you use Auto Discovery on your Memcached cluster, you do not need to change the endpoints in your application as you add or remove nodes.
Scaling cluster vertically (changing node type):
When you scale your Memcached cluster up or down, you must create a new cluster.
Memcached clusters always start out empty unless your application populates it.
Multi-AZ (not automatic): (Ref)
When you create or add nodes to your Memcached cluster, you can specify
different AZ for each node or the same AZ for all your nodes,
allow ElastiCache to choose different AZ for each node or the same AZ for all your nodes.
New nodes can be created in different AZs as you add them to an existing Memcached cluster. Once a cache node is created, its AZ cannot be modified.
Endpoints
Each cache node in a Memcached cluster has its own endpoint.
The cluster has an endpoint called the cluster configuration endpoint.
If you enable Auto Discovery and connect to the configuration endpoint, your application automatically knows each node endpoint, even after adding or removing nodes from the cluster.
For enhanced security, ElastiCache node access is restricted to applications running on whitelisted EC2 instances. You can control the EC2 instances that can access your cluster by using security groups. (Ref)
To connect to a Memcached node, you must first connect to the EC2 instance using the connection utility of your choice, and then use the telnet command to connect to the node or cluster and then run database commands.
ElastiCache eviction occurs when a new item is added and an old item must be removed due to lack of free space.
Scale out by adding more nodes.
Scale up by increasing the memory of existing nodes.
To migrate Memcached nodes from a single AZ to multiple AZs
Modify your cluster by creating new cache nodes in the AZs where you want them:
If you are not using Auto Discovery, update your client application with the new cache node endpoints.
Modify your cluster by removing the nodes you no longer want in the original AZ:
In a cluster, the max_item_size parameter sets the size (bytes) of the largest item that can be stored in the cluster.
The default hash algorithm is jenkins; however, murmur3 can be used if specified with the hash_algorithm parameter.
The ElastiCache Memcached Java and PHP client libraries have consistent hashing turned off by default, whereas it is turned on by default in the .Net library.
Upgrade: Auto OS/security patching, manual Engine Version Upgrade
Redis is a key-value store that supports abstract data types and optional data durability.
Redis can offer not only caching functionality but also Pub/Sub, Sorted Sets and an In-Memory Data Store.
Redis provides native capability for sorted sets which is an ideal solution for complex and compute intensive data structures (e.g. leaderboards).
ElastiCahe can improve latency and throughput for read-heavy applications.
Max 155.17 TiB of in-memory key-value store, Interface: Redis API, Port: 6379
Redis cluster (called replication group in the API/CLI),
Shard (called node group in the API/CLI)
Each shard = max 6 nodes (1 primary + max 5 read replicas). If you have no replicas and a node fails, you experience loss of all data in that shard.
Each node in shard has the same compute, storage, and memory specifications.
ElastiCache uses DNS entries to allow client applications to locate cache servers (Cache Nodes).
Each cache node has its own DNS name and port.
The DNS name for a Cache Node remains constant, but the IP address of a Cache Node can change over time (e.g. when Cache Nodes are auto replaced after a failure).
Redis (cluster mode disabled) vs. Redis (cluster mode enabled)
Redis (cluster mode disabled) can add or delete nodes from the cluster.
Redis (cluster mode enabled) clusters: the structure of the cluster, node type, number of shards, and number of nodes, is fixed at the time of creation and cannot be changed.
Scaling vs. partitioning (Ref)
Redis (cluster mode disabled) supports scaling. You can scale read capacity by adding or deleting replica nodes or scale capacity by scaling up to a larger node type.
Redis (cluster mode enabled) is better for partitioning data across shards, not scaling.
Allow dynamically change the number of shards as your business needs change.
Spread load over a greater number of endpoints, reduce access bottlenecks during peak.
Accommodate a larger data set since the data can be spread across multiple servers.
Reads vs. writes (Ref)
For read-heavy applications, it is preferable to use Redis (cluster mode disabled) clusters that support scaling up or down of read capacity by creating and deleting read replicas within the cluster. However, there is a maximum of 5 read replicas.
For write-heavy applications, it is preferable to use Redis (cluster mode enabled) cluster because it provides multiple write-endpoints (multiple shards) which can be used to distribute traffic for write-heavy applications.
Node type vs. number of nodes
Since Redis (cluster mode disabled) cluster has only one shard, the node type must be large enough to accommodate all the cluster’s data plus necessary overhead.
When using a Redis (cluster mode enabled) cluster, since you can partition your data across several shards, the node types can be smaller, though you need more of them.
ElastiCache does NOT currently support dynamically changing the cache node type for a cache cluster after it has been created. If you wish to change the Node Type of a cache cluster, you will need to set up a new cache cluster with the desired Node Type, and migrate your application to that cache cluster.
Redis (cluster mode disabled) cluster (Ref, Scaling)
1 shard; with 0-5 read replica nodes for each shard
Data partitioning NOT supported.
Promote replica to primary: not automatic
Multi-AZ: optional
For single-node cluster with 0 shards (use the one node for both reads and writes) (Ref)
To change data capacity of a cluster, scale up/down a single-node Redis cache cluster
aws elasticache **modify-cache-cluster**
**--cache-cluster-id** my-redis-cache-cluster
--cache-node-type cache.m3.xlarge
--cache-parameter-group-name redis32-m2-xl
--apply-immediately
For multi-node clusters with 1 shard (1 node as the read/write primary node with 0-5 read replica nodes).
To change data capacity of a cluster, scale up/down a Redis replication group (cluster)
aws elasticache **modify-replication-group**
**--replication-group-id** my-repl-group
--cache-node-type cache.m3.xlarge
--cache-parameter-group-name redis32-m2-xl
--apply-immediately
To change the read capacity of a cluster, add more read replicas (max 5), or remove read replicas.
Redis (cluster mode enabled) cluster (Ref, Shards)
Horizontal scaling (change the number of shards in the cluster)
Online resharding and shard rebalancing, allows scaling in/out while the cluster continues serving incoming requests with no downtime.
Offline resharding and shard rebalancing, in addition to changing the number of shards in your replication group, you can do the following:
Online vertical scaling, which changes the node type to resize the cluster, allows scaling up/down while the cluster continues serving incoming requests.
Max 90 nodes per cluster (soft limit). The node or shard limit can be increased to a max of 500 per cluster.
E.g. If each shard is planned to have 5 replicas, max no. of shards = 90 / (5+1) = 15 shards.
E.g. If each shard is planned to have 5 replicas, max no. of shards = 500 / (5+1) = 83 shards (Ref)
Endpoints (Ref)
Redis standalone node, use the node’s endpoint for both read and write operations.
Redis (cluster mode disabled) clusters
Primary Endpoint is for all write operations.
Reader Endpoint evenly splits incoming connections to the endpoint between all read replicas. A reader endpoint is not a load balancer. It is a DNS record that will resolve to an IP address of one of the replica nodes in a round robin fashion.
Use the individual Node Endpoints for read operations (aka Read Endpoints In API/CLI).
Redis (cluster mode enabled) clusters
The cluster’s Configuration Endpoint is for all operations.
You can still read from individual Node Endpoints (aka. Read Endpoints in API/CLI).
Connecting to a Cluster’s Node (Ref)
Multi-AZ and Automatic failover: optional (Ref, FAQs)
You can use Multi-AZ if you have a cluster consisting of a primary node and one or more read replicas.
Multi-AZ is enabled by default on Redis (cluster mode enabled) clusters, if the cluster contains at least one replica in a different AZ from the primary in all shards.
If Multi-AZ is disabled, ElastiCache replaces a cluster’s failed node by recreating/reprovisioning the failed node.
If Multi-AZ is enabled, a failed primary node fails over to the replica with the least replication lag.
The selected replica is automatically promoted to primary, which is much faster than creating and reprovisioning a new primary node. This process usually takes just a few seconds until you can write to the cluster again.
A replacement read replica is then created and provisioned in the same AZ as the failed primary.
In case the primary failed due to temporary AZ disruption, the new replica will be launched once that AZ has recovered.
Primary endpoint – You don’t need to make any changes to your application, because the DNS name of the new primary node is propagated to the primary endpoint.
Read endpoint – The reader endpoint is automatically updated to point to the new replica nodes.
ElastiCache –automatic-failover-enabled flag is used for multi-AZ automatic failover.
When you manually promote read replicas to primary on Redis (cluster mode disabled), you can do so only when Multi-AZ and automatic failover are disabled. (Ref)
You cannot disable Multi-AZ on Redis (cluster mode enabled) clusters. Therefore, you cannot manually promote a replica to primary on any Redis (cluster mode enabled) cluster.
Whenever the primary is rebooted, it is cleared of data when it comes back online, which in turn, results in the replicas clearing their copy of the data. This results in data loss.
Automatic Backups and Manual Backups
For persistence, Redis supports point-in-time backups (copying the Redis data set to disk). (Ref)
Automatic Backups of the cluster (daily) are retained in S3. Backup retention period: 0 - 35 days
During the backup process, you cannot run any other API or CLI operations on the cluster.
During any contiguous 24-hour period, you can create no more than 20 manual backups per node in the cluster.
You can export a backup to a S3 bucket so you can access it from outside ElastiCache. (Ref)
Exporting a backup can be helpful if you need to launch a cluster in another Region.
The ElastiCache backup and the S3 bucket that you want to copy it to must be in the same Region.
To create a final backup of an ElastiCache Redis cluster (Ref)
If you delete a cluster and request a final backup, ElastiCache always takes the backup from the primary node. This ensures that you capture the very latest Redis data, before the cluster is deleted.
Redis (cluster mode disabled) cluster
Backups (Snapshots): A single .rdb file.
Restore data to a new cluster using a single .rdb file from a Redis (cluster mode disabled) cluster.
Backup and restore aren’t supported on cache.t1.micro nodes. All other cache node types are supported.
Redis (cluster mode enabled) cluster
Backups (Snapshots): A .rdb file for each shard.
Restore data to a new cluster .rdb files from either a cluster mode disabled or cluster mode enabled cluster.
Support taking backups on the cluster level; NOT at the shard level.
When seeding a new ElastiCache Redis cluster from a backup file, if the backup does not fit in the memory of the new node, the resulting cluster will have a status of restore-failed. If this happens, you must delete the cluster and start over.
An ElastiCache:SnapshotFailed event means that ElastiCache was unable to populate the cache cluster with Redis snapshot data.
If you experience performance issues occur during the ElastiCache automated backup window, (4)
Create backups from one of the read replicas.
Set the reserved-memory-percentage parameter (to 25% recommended), which specifies the amount of memory available for non-data use (background processes).
If you experience performance issues because the ElastiCache cluster does not have sufficient memory allocated for non-data use, create a custom parameter group with reserved-memory-percent parameter to 50. Apply the custom parameter group to the cluster.
A large and sustained spike in the number of concurrent connections indicates there has been either
a large, sustained traffic spike or
the application is not releasing connections as it should.
In a Redis ElastiCache cluster, the timeout parameter can be set in order for Redis to disconnect idle clients.
Multi-region: Global Datastore feature can be used to create cross-region read replica clusters.
Global Datastores (Ref, Image)
Each global datastore is a collection of one or more clusters that replicate to one another.
The Primary (active) cluster accepts writes that are replicated to all clusters within the global datastore. A primary cluster also accepts read requests.
A Secondary (passive) cluster only accepts read requests and replicates data updates from a primary cluster. A secondary cluster needs to be in a different Region than the primary cluster.
ElastiCache manages automatic, asynchronous replication of data between the two clusters.
Advantages
Geolocal performance – you can reduce latency of data access in that Region.
Disaster recovery – If your primary cluster in a global datastore experiences degradation, you can promote a secondary cluster as your new primary cluster (manually).
ElastiCache does NOT support autofailover from one Region to another. When needed, you can promote a secondary cluster as the new primary cluster manually.
All primary and secondary clusters in your global datastore should have the same number of primary nodes, node type, engine version, and number of shards (in case of cluster-mode enabled).
Each cluster in your global datastore can have a different number of read replicas to accommodate the read traffic local to that cluster.
You can scale regional clusters both vertically (scaling up and down) and horizontally (scaling in and out). You can scale the clusters by modifying the global datastore. All the regional clusters in the global datastore are then scaled without interruption.
Replication must be enabled if you plan to use an existing single-node cluster.
You can work with global datastores only in VPC clusters.
Global datastores support pub/sub messaging with the following stipulations:
For cluster-mode disabled, pub/sub is fully supported. Events published on the primary cluster of the primary Region are propagated to secondary Regions.
For cluster mode enabled, the following applies:
For published events that aren’t in a key space, only subscribers in the same Region receive the events.
For published key space events, subscribers in all Regions receive the events.
To cancel a subscription to a single Redis pub/sub channel, you should use the UNSUBSCRIBE command specifying the channel you want to cancel.
Encryption: optional, applies to disk during sync, backup and swap operations, backups stored in S3.
Access Control and server authentication
Use Redis AUTH which gives all users the same permissions if the Token provided is a match,
Use the User Group Access Control List as the Access Control Option. This allows you to authenticate users on a Role Based Access Control method (RBAC).
Upgrade: Auto OS/security patching, manual Engine Version Upgrade
If you create an IAM role in your AWS account with permissions to create a cache cluster, and someone who assumes the role creates a cluster, then who will own the cache cluster resource?
add-tags-to-resource can be used to add or modify the value of a tag from an existing ElastiCache resource.
Redshift is a peta-byte scale relational columnar datastore used as a data warehouse and optimized for reporting and business intelligence applications.
Redshift databases are designed as analytical repositories. They can store aggregate values from transactional databases and dozens of other source locations.
Redshift databases are compatible with all data types, although semistructured and unstructured data may require preprocessing before it can be loaded into the data warehouse.
Redshift is not suitable for ingestion of data at low latency.
Data warehouses are not used to store highly detailed records.
Max 8 PB, Interface SQL, Port (TCP) 5439
Upgrade: Auto Cluster version upgrade (periodically), version options: Current, Trailing, Preview
Single-AZ: (Ref)
Redshift only supports Single-AZ deployments.
You can run data warehouse clusters in multiple AZ’s by loading data into two Redshift data warehouse clusters in separate AZs from the same set of S3 input files.
You can restore a data warehouse cluster to a different AZ from your data warehouse cluster snapshots.
With Redshift Spectrum, you can spin up multiple clusters across AZs and access data in S3 without having to load it into your cluster.
No Failover. In the event of individual node failure:
Redshift will automatically detect and replace a failed node in your data warehouse cluster.
The data warehouse cluster will be unavailable for queries and updates until a replacement node is provisioned and added to the DB.
Redshift makes your replacement node available immediately and loads your most frequently accessed data from S3 first to allow you to resume querying your data as quickly as possible.
Single node clusters do not support data replication. Recommend using at least 2 nodes for production.
In the event of a drive failure, you will need to restore the cluster from snapshot on S3.
If AZ has an outage, Redshift will automatically move your cluster to another AZ without any data loss or application changes. To activate this, enable the relocation capability in your cluster configuration settings.
Disaster recovery (in case of one of the Region fails),
Configure Redshift to automatically copy snapshots (either automated or manual) for a cluster to another region.
When a snapshot is created in the cluster’s primary region, it is copied to a secondary region; these are known as the source region and destination region.
Then you have the ability to restore your cluster from recent data if anything affects the primary region.
Scaling (changing the node type and number of nodes) (Ref)
Elastic resize
Use elastic resize to change the node type, number of nodes, or both.
If you only change the number of nodes, then queries are temporarily paused and connections are held open if possible.
During the resize operation, the cluster is read-only.
Typically, elastic resize takes 10-15 mins.
Classic resize
Use classic resize to change the node type, number of nodes, or both.
Choose this option when you are resizing to a configuration that isn’t available through elastic resize.
During the resize operation, the cluster is read-only.
Typically, classic resize takes 2 hours - 2 days or longer, depending on your data’s size.
Snapshot and restore with classic resize
Encryption: KMS or HSM or None, applies to cluster’s storage volume, data, indexes, logs, automated backups, and snapshots.
Automatic Backups and Manual Snapshots
Automatic Backup retention period: 0 - 35 days (default 1 day). If you disable automated snapshots, Redshift stops taking snapshots and deletes any existing automated snapshots for the cluster.
Redshift snapshots are stored on S3.
The default retention period for copied snapshots is 7 days and it only applies to automated snapshots.
Redshift always attempts to maintain at least 3 copies of your data (the original and replica on the compute nodes, and a backup in S3).
Redshift can also asynchronously replicate your snapshots to S3 in another region for disaster recovery.
The automated backup and manual cluster snapshots include
Public tables
Labels
Replica tables
BUT NOT System tables
To copy an Redshift cluster from a production AWS account to a non-production AWS account.
To copy encrypted RedShift snapshots to another region
If working from the CLI, create a snapshot copy grant in the destination Region for a KMS key in the destination Region. Configure Redshift cross-Region snapshots in the source Region.
If working from the console, Redshift provides the proper workflow to configure the grant when you enable cross-Region snapshot copy.
Audit logging is not enabled by default in RedShift. If logging is enabled, the logs are stored in S3.
Redshift clusters are composed of nodes. Compute nodes divide work among slices. Each slice is assigned a portion of the node’s memory and drive space. When you connect to a Redshift cluster, you use the SQL endpoint.
Single-node cluster vs. Multi-node cluster
Single-node cluster enables you to get started with Redshift quickly and cost-effectively and scale up to a multi-node configuration as your needs grow.
Multi-node cluster requires a leader node that manages client connections and receives queries, and two compute nodes that store data and perform queries and computations. The leader node is provisioned for you automatically and you are not charged for it.
Redshift single-node does not support replication.
Redshift multi-node clusters support node recovery.
Redshift Spectrum can be used to efficiently query and retrieve structured and semistructured data from files in S3 without having to load the data into Redshift tables.
Connecting to the Leader node
The leader node is the only node in your cluster you can directly connect to.
The SQL endpoints provided by AWS are the DNS of the leader node.
Typically you connect using a SQL client and a JDBC or ODBC driver.
SQL Clients: Postico, MySQL Workbench, Command Line SQL tools
SQL Drivers: JDBC, ODBC
SQL Queries: not exactly the same as PostgreSQL
Compute Node Types
Dense compute (dc) nodes provide less storage space but improved performance with SSDs and higher IO.
Dense storage (ds) nodes provide significantly higher amounts of storage but less performance.
Max of 128 nodes of the large sizes.
Security
Redshift is secured at the cluster level, not the node level.
You can encrypt data using keys you manage through KMS.
Connections to the database are secured using HTTPS.
IAM is used to authorize and authenticate users to Redshift clusters.
Redshift clusters are run inside of a VPC. You can use a VPN to connect your on-premises data center to Redshift, but it does not contain or isolate a Redshift cluster.
Security Group Inbound Rule: Type=”Redshift (5439)”, Protocol=”TCP (6)”
You cannot change the port number for your Redshift cluster after it is created
Load data
To validate the data in the S3 input files or DynamoDB table before you actually load the data in Redshift, use the NOLOAD option with the COPY command.
You can load data from EMR using the
Hadoop Distributed File System (HDFS), or
Custom bootstrap action.
If a scheduled maintenance occurs while a query is running, the query is terminated and rolled back and you need to restart it. (Ref)
To minimize data load problems caused by a maintenance window
Schedule VACUUM operations to avoid future maintenance windows
Re-execute queries or transactions that were terminated and rolled back
S3ServiceException Errors (Source-1)
System Tables for troubleshooting data loads (Source-1)
Query STL_LOAD_ERRORS to discover the errors that occurred during specific loads.
Query STL_FILE_SCAN to view load times for specific files or to see if a specific file was even read.
Query STL_S3CLIENT_ERROR to find details for errors encountered while transferring data from S3.
Multibyte Character Load Errors (Source-1)
You want to test the performance of your Redshift cluster and see the baseline of some queries on your tables. You make a new query and test it. The first query executes in 300s. You rerun the same query, which executes in 150s. What would explain the difference in the execution time?
The first query includes the compilation time.
In Redshift, when you compare query execution times, do not count the first time the query is executed, because the first run time includes the compilation time.
You’ve noticed that your VPN connection to Redshift appears to hang or timeout when running long queries, such as a COPY command. You observe that the Redshift console displays the completion of the query, but the client tool itself still appears to be running the query and results are incomplete. What are some ways to troubleshoot this problem?
This happens when you connect to Redshift from a computer other than an EC2 instance, and idle connections are terminated by an intermediate network component, such as a firewall, after a period of inactivity. This behavior is typical when you log in from a VPN or your local network.
To avoid these timeouts, Redshift recommends these changes:
Increase client system values that deal with TCP/IP timeouts. You should make these changes on the computer you are using to connect to your cluster. The timeout period should be adjusted for your client and network.
Optionally, set keep-alive behavior at the DNS level.
You have a Lambda function that creates the same number of records in both DynamoDB and Redshift. You checked the number of their concurrent executions and found that the concurrent executions count does not match.
One record in Redshift equates to two records in DynamoDB Stream.
Concurrent executions refers to the number of executions of your function code that are happening at any given time. You can estimate the concurrent execution count, but the concurrent execution count will differ depending on whether or not your Lambda function is processing events from a stream-based event source. Since DynamoDB stream is stream-based and Redshift is not, it’s normal for the concurrent execution count to differ.
More Redshift Details
Redshift performance data (both CloudWatch metrics and query and load data) is recorded every minute.
Billing: Concurrency Scaling and Redshift Spectrum are optional features of Redshift that you will be billed for if enabled.
In Redshift, the masteruser, which is the user you created when you launched the cluster, is a superuser. Database superusers have the same privileges as database owners for all databases. You must be a superuser to create a superuser. To create a new database superuser, log on to the database as a superuser and issue a CREATE USER command or an ALTER USER command with the CREATEUSER privilege.
To make a table read-only for everyone including the object owners
The object owners can revoke their own ordinary privileges using the REVOKE command and then make the table read-only for themselves as well as others.
The right to modify or destroy an object is always the privilege of the owner only.
The privileges of the object owner, such as DROP, GRANT, and REVOKE privileges, are implicit and cannot be granted or revoked.
Object owners can revoke their own ordinary privileges, for example, to make a table read-only for themselves as well as others. Superusers retain all privileges regardless of GRANT and REVOKE commands.
Performance Tuning
Redshift can run queries across petabytes of data in Redshift itself and exabytes of data in S3.
Redshift can achieve its massive speed improvements by implementing columnar indexing of the data and parallel processing.
When you create tables in Redshift
Differences and Optimizations
Uniqueness, primary key, and foreign key constraints are informational only; they are not enforced by Redshift.
By default, Redshift stores data in its raw, uncompressed format. You can apply a compression type, or encoding, to the columns in a table manually when you create the table, or you can use the COPY command to analyze and apply compression automatically.
Data compression allows for significant performance improvements.
Different compression methods are offered when creating tables.
Tools are provided to determine the most effective compression algorithms.
Though users can specify encodings for compression, automatic compression produces the best results.
Delta encoding is very useful for datetime columns.
Columnar storage
Data is stored column-by-column, not row-by-row.
Give significant performance gain if just interact with data from one column.
Columnar storage allows for more effective compression.
Zone Maps
A chunk of data with metadata that can be evaluated to determine if a query even needs to interact with the chunk to execute.
In-memory MIN and MAX values to optimize queries and prune blocks that cannot contain data.
Zonal deployment
Redshift stores DATE and TIMESTAMP data more efficiently than CHAR or VARCHAR, which results in better query performance.
Designed for large writes
Batch processing and high parallelism means Redshift is optimized for large amounts of data.
Small writes of 1-100 rows have similar cost to larger writes of ~100k rows.
To clean up tables after a bulk delete, a load, or a series of incremental updates, you need to run the VACUUM command, either against the entire database or against individual tables.
When you create a table in Redshift, you designate one of three distribution styles; EVEN, KEY, or ALL.
Redshift provides access to the following types of system tables:
Max 64 TB per database cluster, Interface: subset of MongoDB API
Database port: 27102
A cluster consists of 0 - 16 instances.
One primary DB instance, supports read/write operations, performs all the data modifications to the cluster volume.
A cluster volume is where data is stored. It is a single, virtual volume that uses solid-state disk (SSD) drives and designed for reliability and high availability. The cluster volume consists of copies of the data across 3 AZs in a single Region.
0-15 Read replicas, support only read operations,connect to the same storage volume as the primary instance.
Endpoints of a cluster
One cluster endpoint, connects to the current primary DB instance for the DB cluster.
Example endpoint: sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27012
The cluster endpoint can be used for read and write operations.
The cluster endpoint provides failover support for read and write connections to the cluster. If your cluster’s current primary instance fails, and your cluster has at least one active read replica, the cluster endpoint automatically redirects connection requests to a new primary instance.
One reader endpoint provides automatic load-balancing support for read-only connections to the DB cluster.
Example endpoint: sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27012
Each Aurora DB cluster has one reader endpoint.
If the cluster only contains a primary instance and no read replicas, the reader endpoint connects to the primary instance.
When you add a replica instance to a cluster, the reader endpoint opens read-only connections to the new replica after it is active.
The reader endpoint load balances read-only connections, not read requests. If some reader endpoint connections are more heavily used than others, your read requests might not be equally balanced among instances in the cluster. It is recommended to distribute requests by connecting to the cluster endpoint as a replica set and utilizing the secondaryPreferred read preference option.
Attempting to perform a write operation over a connection to the reader endpoint results in an error.
An instance endpoint per each instance, connects to a specific DB instance.
Example endpoint: sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27012
The instance endpoint provides direct control over connections to the DB cluster, for scenarios where using the cluster endpoint or reader endpoint might not be appropriate.
The instance endpoint for the current primary instance can be used for read and write operations.
Attempting to perform write operations to an instance endpoint for a read replica results in an error.
Use case: Provisioning for a periodic read-only analytics workload.
You can provision a larger-than-normal replica instance, connect directly to the new larger instance with its instance endpoint, run the analytics queries, and then terminate the instance. Using the instance endpoint keeps the analytics traffic from impacting other cluster instances.
Replica Set Mode
You can connect to your DocumentDB cluster endpoint in replica set mode by specifying the replica set name rs0.
Connecting in replica set mode provides the ability to specify the options: (read-consistency)
Read Concern
Write Concern, and
Read Preference .
When you connect in replica set mode, your DocumentDB cluster appears to your drivers and clients as a replica set. Instances added and removed from your DocumentDB cluster are reflected automatically in the replica set configuration.
Each DocumentDB cluster consists of a single replica set with the default name rs0. The replica set name cannot be modified.
Connecting to the cluster endpoint in replica set mode is the recommended method for general use.
All instances in a DocumentDB cluster listen on the same TCP port for connections.
Example connection string: mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
Scaling - Storage (Ref, high water mark)
Storage will automatically grow, up to 64 TB, in 10GB increments with no impact to database performance. The size of your cluster volume is checked on an hourly basis.
Scaling down is NOT supported. Storage costs are based on the storage “high water mark” (the maximum amount allocated to your DocumentDB cluster at any time during its existence)
Avoid ETL practices that create large amounts of temporary information, or that load large amounts of new data prior to removing unneeded older data.
You can determine what the “high water mark” is currently for your DocumentDB cluster by monitoring the VolumeBytesUsed CloudWatch metric.
If removing data from a DocumentDB cluster results in a substantial amount of allocated but unused space, resetting the high water mark requires doing a logical data dump and restore to a new cluster, using a tool such as mongodump or mongorestore.
Creating and restoring a snapshot does NOT reduce the amount allocated storage, because the physical layout of the underlying storage remains unchanged.
Scaling - Instance Scaling
Scale your DocumentDB cluster as needed by modifying the instance class for each instance in the cluster. DocumentDB supports several instance classes that are optimized for DocumentDB.
db.r4.large is the smallest instance class for DocumentDB instances.
Set another alarm for replication lags that exceed 10s. If you surpass this threshold for multiple data points, scale up your instances or reduce your write throughput on the primary instance.
Scaling - Read Scaling
Create up to 15 replicas in the DB cluster. Read replicas don’t have to be of the same DB instance class as the primary instance.
DocumentDB replica returns with minimal replication lag less than 100 milliseconds.
To read scale with DocumentDB, we recommend that you connect to your cluster as a replica set and distribute reads to replica instances using the built-in read preference capabilities of your driver.
Scaling - Write Scaling (manual)
Add a replica of a larger instance type to your cluster.
Set the failover tier on the new replica to priority zero, ensuring a replica of the smaller instance type has the highest failover priority.
Initiate a manual failover to promote the new replica to be the primary instance.
This will incur ~30 seconds of downtime for your cluster. Please plan accordingly.
Remove all replicas of an instance type smaller than your new primary from the cluster.
Set the failover tier of all instances back to the same priority (usually, this means setting them back to 1)
Multi-AZ and automatic failover (Ref, failover)
DocumentDB features fault-tolerant, self-healing storage that replicates six copies of your data across 3 AZs.
In a DocumentDB cluster, DocumentDB provisions and automatically distributes instances across the AZs in the subnet group (must be at least 2 AZs) to balance the cluster (prevents all instances from being located in the same AZ).
If you have a DocumentDB replica instance in the same or different AZ when failing over: DocumentDB flips the CNAME for your instance to point at the healthy replica, which is, in turn, promoted to become the new primary. Failover typically completes within 30 seconds from start to finish.
If you don’t have a DocumentDB replica instance (for example, a single instance cluster): DocumentDB will attempt to create a new instance in the same AZ as the original instance. This replacement of the original instance is done on a best-effort basis and may not succeed if, for example, there is an issue that is broadly affecting the AZ.
To force a failover, use the failover-db-cluster operation with these parameters.
–db-cluster-identifier
–target-db-instance-identifier <name of the instance to be promoted to primary(optional)
DocumentDB provides you with failover tiers as a means to control which replica instance is promoted to primary when a failover occurs.
Each replica instance is associated with a failover tier (0–15). When a failover occurs due to maintenance or an unlikely hardware failure, the primary instance fails over to a replica with the lowest numbered priority tier. If multiple replicas have the same priority tier, the primary fails over to that tier’s replica that is the closest in size to the primary.
By setting the failover tier for a group of select replicas to 0 (the highest priority), you can ensure that a failover will promote one of the replicas in that group. You can effectively prevent specific replicas from being promoted to primary in case of a failover by assigning a low-priority tier (high number) to these replicas. This is useful in cases where specific replicas are receiving heavy use by an application and failing over to one of them would negatively impact a critical application.
Backup retention period: 1 - 35 days (i.e. always on)
Encryption: optional, applies to cluster’s storage volume, data, indexes, logs, automated backups, and snapshots
Access control
DocumentDB does not support resource-based policies.
IAM Policies control access to DocumentDB API actions and DocumentDB clusters and instances, not databases.
Use db.grantRolesToUser command is used for assigning DocumentDB database roles to DocumentDB database users.
E.g. db.grantRolesToUser(“Bob”, ({role: “read”, db: “production”})).
Security DocumentDB
Upgrade: Auto OS/security patching, manual Engine Version Upgrade
Performance tuning for DocumentDB
DocumentDB Profiler feature can be enabled to log the details (including execution time) of MongoDB operations to CloudWatch Logs.
CloudWatch Logs Insights can then be used to analyze the data and investigate slow queries. (Ref)
When a DocumentDB cluster takes a long time to return query results, use the db.runCommand with MongoDB explain() method to obtain a detailed query execution plan and insight into the query performance.
When a DocumentDB cluster takes a long time to return query results:
Create an index on the field being queried (speeds up the query operations).
Set the “secondaryPreferred” read preference option distributes requests to read replicas. This is recommended as it increases performance efficiency of the database cluster.
How to identify blocked queries on a DocumentDB cluster?
Neptune is a fully-managed, purpose-built, high-performance graph database optimized for storing billions of relationships (highly connected datasets) and querying the graph with milliseconds latency.
Neptune leverages operational technology that is shared with RDS (Aurora).
Max 64 TiB Neptune cluster volume, max 64 TiB graph size. Interface: subset of Gremlin and SPARQL
Database port: 8182
Neptune supports query languages:
Apache TinkerPop Gremlin, is a graph traversal language used with the Property Graph (PG) model.
RDF/SPARQL, is the query language used with RDF models to describe relationships between graph objects.
A cluster consists of 0 - 16 instances.
One primary DB instance, supports read/write operations, performs all the data modifications to the cluster volume.
A cluster volume is where data is stored. It is a single, virtual volume that uses solid-state disk (SSD) drives and designed for reliability and high availability. The cluster volume consists of copies of the data across 3 AZs in a single Region.
0-15 Read replicas, support only read operations,connect to the same storage volume as the primary instance.
Endpoints of a cluster (Ref)
One cluster endpoint, connects to the current primary DB instance for the DB cluster.
Example endpoint: sample-cluster.cluster-123456789012.us-east-1.neptune.amazonaws.com:8182
You use the cluster endpoint for all write operations on the DB cluster, including inserts, updates, deletes, and DDL (data definition language) and DML (data manipulation language) changes.
You can also use the cluster endpoint for read operations, such as queries.
One reader endpoint, directs each connection request to one of the Neptune replicas.
Example endpoint: sample-cluster.cluster-ro-123456789012.us-east-1.neptune.amazonaws.com:8182
If the cluster only contains a primary instance and no read replicas, the reader endpoint connects to the primary instance. In that case, you can also do write-operations through the endpoint.
The reader endpoint provides round-robin routing for read-only connections to the DB cluster. Use the reader endpoint for read operations, such as queries.
The reader endpoint round-robin routing works by changing the host that the DNS entry points to. Each time you resolve the DNS, you get a different IP, and connections are opened against those IPs. After a connection is established, all the requests for that connection are sent to the same host.
The client must create a new connection and resolve the DNS record again to get a connection to a potentially different read replica.
Problem: DNS caching for clients or proxies resolves the DNS name to the same endpoint from the cache. This is a problem for both round robin routing and failover scenarios.
Neptune does not load balance. The reader endpoint only directs connections to available Neptune replicas in a Neptune DB cluster. It does not direct specific queries.
An instance endpoint per each instance, connects to a specific DB instance.
Example endpoint: sample-instance.123456789012.us-east-1.neptune.amazonaws.com:8182
The instance endpoint provides direct control over connections to the DB cluster, for scenarios where using the cluster endpoint or reader endpoint might not be appropriate.
Multi-AZ and automatic failover (optional), (FAQs)
Neptune stores copies of the data in a DB cluster across multiple AZs in a single Region, regardless of whether the instances in the DB cluster span multiple AZs.
When you create Neptune replicas across AZs, Neptune automatically provisions and maintains them synchronously.
Neptune automatically fails over to a Neptune replica in case the primary DB instance becomes unavailable.
To maximize availability, place at least one replica in a different AZ from the primary instance.
You can specify the fail-over priority for Neptune replicas.
If you have a Neptune Replica, in the same or a different AZ, when failing over, Neptune flips the CNAME for your DB primary endpoint to a healthy replica, which is in turn is promoted to become the new primary. Start-to-finish, failover typically completes within 30 seconds. Additionally, the read replicas endpoint does not require any CNAME updates during failover.
If you do not have a Neptune Replica (i.e. single instance), Neptune will first attempt to create a new DB Instance in the same AZ as the original instance. If unable to do so, Neptune will attempt to create a new DB Instance in a different AZ. From start to finish, failover typically completes in under 15 minutes.
Neptune Storage Auto-Repair detects segment failures in the SSDs and repairs segments using the data from the other volumes in the cluster (Ref).
Scaling - Storage Scaling (Ref)
Storage will automatically grow, up to 64 TB, in 10GB increments with no impact to database performance. The size of your cluster volume is checked on an hourly basis.
Scaling down is NOT supported. Storage costs are based on the storage “high water mark” (the maximum amount allocated to your Neptune DB cluster at any time during its existence)
Avoid ETL practices that create large amounts of temporary information, or that load large amounts of new data prior to removing unneeded older data.
You can determine what the “high water mark” is currently for your Neptune DB cluster by monitoring the VolumeBytesUsed CloudWatch metric.
If a substantial amount of your allocated storage is not being used, the only way to reset the high water mark is to export all the data in your graph and then reload it into a new DB cluster.
Creating and restoring a snapshot does not reduce the amount allocated storage, because the physical layout of the underlying storage remains unchanged.
Scaling - Instance Scaling
Scaling - Read Scaling
Loading data into Neptune (Ref)
From S3
# import.sh
curl -X POST
-H 'Content0Type: application/json'
my-neptune-database.xxxxxx.us-east-1.neptune.amazonaws.com:8182/loader
-d '
{
"source": "s3://database-demp/neptune/",
"format": "csv",
"iamRoleArn":
"arn:aws:iam::xxxxxxxxxxxx:role/NeptuneLoadFromS3",
"Region": "us-east-1",
"failOnError": "FALSE",
"Parallelism": "MEDIUM"
}'
Database Cloning (similar as RDS)
Neptune Streams
Backup and Restore
Automatic Backups: Backup retention period: 1 - 35 days (always on)
Neptune automatically monitors and backs up your database to S3, enabling granular PITR.
If you delete a DB cluster, all its automated backups are deleted at the same time and cannot be recovered.
Monitor CloudWatch metric BackupRetentionPeriodStorageUsed
Manual Snapshots
Manual snapshots are not deleted when the cluster is deleted.
Monitor CloudWatch metric SnapshotStorageUsed
CloudWatch metric TotalBackupStorageBilled = BackupRetentionPeriodStorageUsed + SnapshotStorageUsed
Encryption: optional, applies to all logs, backups, and snapshots (Ref)
If a KMS key identifier is not provided, Neptune uses your default RDS encryption key (aws/rds) for your new Neptune DB instance.
After you create an encrypted Neptune DB instance, you cannot change the encryption key for that instance.
You cannot enable encryption for a DB instance after it has been created.
You cannot create an encrypted Neptune replica for an unencrypted Neptune DB cluster. You cannot create an unencrypted Neptune replica for an encrypted Neptune DB cluster.
Encrypted Read Replicas must be encrypted with the same key as the source DB instance.
You cannot convert an unencrypted DB cluster to an encrypted one.
Secure access to and within a Neptune database (Ref)
256-bit AES data encryption
AWS IAM
HTTPS
IAM DB Authentication: optional (Ref)
Upgrade: manual Engine Version Upgrade: using latest cluster engine version / older cluster engine version
Performance tuning
Neptune does not require you to create specific indices to achieve good query performance.
With support for up to 15 read replicas, Neptune can support 100,000s of queries per second.
Neptune uses query optimization for both SPARQL queries and Gremlin traversals.
Change sets enable the preview of proposed changes to a stack in order to assess the impact on existing resources.
StackSets facilitate deployment and management of CloudFormation templates across multiple AWS accounts.
Stack Policies can be used to deny actions on specific stack or resources to protect them from unintended modifications.
E.g. To prevent accidental replacements or deletions of the production DDB when a template update is applied
{"Effect": "Deny", "Action": "Update:*", "Principal": "*",
"Resource": "LogicalResourceId/ProductionDatabase" }
CloudFormation Registry provides a listing of available CloudFormation providers in an account that can be used in CloudFormation templates.
CloudFormation Rolling updates dictate how CloudFormation handles deployment updates to resources.
Secrets Manager can be used to securely store, retrieve, and automatically rotate database credentials.
Systems Manager Parameter Store does not provide automatic credentials rotation capability.
KMS is used for management of cryptographic keys.
Resource Access Manager service is used for managing access to AWS resources between multiple accounts.
Secrets Manager is used to store the database credentials for a RDS PostgreSQL. How soon after enabling automatic rotation will the credential first be rotated?
Secrets Manager offers the ability to automatically rotate your secrets and passwords, keeping in line with normal 30- and 60-day rotation guidelines that many corporations will have. (Ref)
This functionality has been integrated with RDS, Redshift, and DocumentDB.
And the most powerful feature of all is that all these interactions can be implemented as simple API calls.
Dynamic reference patterns
SSM parameter (e.g. use version 2 of the S3AccessControl parameter)
""
SSM secure string parameter
""
Secrets Manager secret
''
Secrets Manager secret (of another account)
’’
Which option would you use in CloudFormation to reference version 2 of a parameter named S3AccessControl that is stored in plain text?
“AccessControl”: “”
Secrets Manager can be used for managing DB credentials when deploying an RDS instance with CF template.
{
"MyRDSInstance": {
"Type": "AWS::RDS::DBInstance",
"Properties": {
"DBName": "MyRDSInstance",
"AllocatedStorage": "20",
"DBInstanceClass": "db.t2.micro",
"Engine": "mysql",
"MasterUsername": "",
"MasterUserPassword": ""
}
}
}
When using CodeBuild to deploy an application that requires to connect to an external database with database credentials being managed by Secrets Manager, the reference to the database credentials can be specified in the BuildSpec file, as a specification of build commands and settings.
env:
secrets-manager:
key: secret-id:json-key:version-stage:version-id
IAM database authentication ( RDS Ref, Aurora Ref, Neptune Ref )
Support only for RDS MySQL, RDS PostgreSQL, Aurora MySQL, Aurora PostgreSQL, Neptune
Authenticate to your DB cluster using IAM Database Authentication (token instead of a password).
Each token expires 15 minutes after creation.
Use IAM database authentication when your application requires fewer than 200 new IAM database authentication connections per second.
IAM database authentication is NOT supported for CNAMEs.
Aurora MySQL parallel query does NOT support IAM database authentication.
To enable IAM database authentication
Enable IAM database authentication on the Aurora cluster.
To allow an IAM user or role to connect to your DB cluster, you must create an IAM policy and attach the policy to an IAM user or role.
"Action": "rds-db:connect",
"Resource": "arn:aws:rds-db:us-east-2:1234567890:dbuser:cluster-ABCDEFGHIJKL01234/db_userx"
# Or connecting to a database through RDS Proxy
"Resource": "arn:aws:rds-db:us-east-2:1234567890:dbuser:prx-ABCDEFGHIJKL01234/db_userx")
# db_userx is the name of the database account to associate with IAM authentication.
Create a database account using IAM authentication
The specified database account should have the same name as the IAM user or role.
No need to assign database passwords to the user accounts you create.
If you remove an IAM user that is mapped to a database account, you should also remove the database account with the DROP USER statement.
MySQL: authentication is handled by AWSAuthenticationPlugin - Connect to the DB cluster, and:
CREATE USER db_userx IDENTIFIED WITH AWSAuthenticationPlugin AS 'RDS';
PostgreSQL: connect to the DB cluster, create database users and then grant them the rds_iam role.
CREATE USER db_userx;
GRANT rds_iam TO db_userx;
To authenticate and access a RDS MySQL database instance (Ref)
Generate an authentication token using aws rds generate-db-auth-token CLI command.
RDSHOST="rdsmysql.cdgmuqiadpid.us-west-2.rds.amazonaws.com"
TOKEN="$(**aws rds generate-db-auth-token** --hostname $RDSHOST
--port 3306 --region us-west-2 --username jane_doe)"
mysql --host=$RDSHOST --port=3306
--ssl-ca=/sample_dir/rds-combined-ca-bundle.pem
--enable-cleartext-plugin --user=jane_doe --password=$TOKEN
A company security policy mandates that all connections to databases must be encrypted. How should the user configure the connection parameters so that the client connection is protected against man-in-the-middle attack?
Aurora MySQL DB cluster (using mysql to connect):
(Ref)
--ssl-mode=verify-full --ssl-ca=/home/myuser/rds-combined-ca-bundle.pem
Aurora PostgreSQL DB cluster: Set rds.force_ssl parameter to 1
RDS SQL Server: encrypt=true;trustServerCertificate=false
RDS Oracle: Set ssl_server_dn_match property to true
(Ref)
The root certificate for enforcing all connections to RDS databases to be encrypted in transit using SSL/TLS (Ref)
Three types of SGs are used with RDS (Ref)
A VPC security group controls access to DB instances and EC2 instances inside a VPC.
A DB security group controls access to EC2-Classic DB instances that are not in a VPC.
An EC2-Classic security group controls access to an EC2 instance.
If your DB instance is in a VPC but isn’t publicly accessible, you can also use an AWS Site-to-Site VPN connection or an Direct Connect connection to access it from a private network.
What solution would establish a connection to the Aurora Serverless cluster from the Lambda function?
An application consists of a front end hosted on EC2 instances in a public VPC subnet and an RDS database in a private VPC subnet. When attempting to establish a connection to the database, the application times out.
Which would be the recommended subnet for hosting an RDS database instance in this VPC?
Subnet1 contains a route table entry with destination: 0.0.0.0/0 and
target: VPC Internet Gateway ID
Subnet2 contains a route table entry with destination 0.0.0.0/0 and
target: NAT Gateway ID
Subnet3 contains an EC2 instance that serves as a bastion host
1. Subnet 2. Security best practice would state that RDS database
instances should be deployed to a private subnet. A private subnet
would only have private IP's with no direct access to the public
internet. Outbound connectivity would be provided via a NAT
gateway.
A company business intelligence team has a number of reporting applications deployed on EC2 instances in their AWS account. The company data warehouse team has provisioned a new set of databases using RDS in a different AWS account. What is the optimal solution to achieve secure and reliable connectivity from the business intelligence applications to the new RDS databases?
VPC Peering is used to establish connectivity between two VPCs over Amazon’s backbone network.
PrivateLink endpoints are used to integrate AWS services to VPC without the use of IGW.
Site-to-site VPN is not the optimal solution as it requires creation of VPN gateways.
DX can be used to establish secure private connections between on-premise network and VPC over a dedicated line.
A company is migrating their on-premise data warehouse to Amazon Redshift. What methods can be used to establish a private connection from on-premise network to Amazon Redshift?
Direct Connect can be used to establish a secure and private connection between on-premise network and VPC over a dedicated line.
Site-to-site VPN can be used to establish a secure and private connection between an on-premise network and VPC over the Internet.
A company is migrating their on-premise MongoDB database to Amazon DynamoDB. Security team mandates that all data must be transferred over a dedicated, private, and secured connection with no data transport occurring over the public Internet. What AWS services must be part of the solution?
Direct Connect can be used to establish a secure and private connection between on-premise network and VPC over a dedicated line.
PrivateLink Gateway Endpoint is used to integrate DynamoDB to VPC without the use of IGW.
A solution architect would like to integrate a RDS for SQL Server instance with an existing Active Directory Domain.
ACID (Atomicity, Consistency, Isolation, Durability)
BASE (Basically, Available, Soft state, Eventually consistent)
Frequent access to data over an extended period
Short-term, low-latency access to temporary data
Infrequent access to an older dataset
ElastiCache vs. RDS Read Replica
Neptune use cases
Athena vs. Redshift Spectrum vs. Aurora
Interface: CQL (Cassandra Query Language)
In Cassandra, a keyspace is a grouping of tables that are related and used by your applications to read and write data.
In each Keyspaces table in Cassandra, there will be a primary key that consists of a partition key and one or more columns.
How can you run queries using CQL?
With QLDB, you can rest assured that nothing has changed or can be changed through the use of a database journal, which is configured as append-only.
Data for a QLDB database is placed into tables of Amazon Ion documents.
{kind=link}
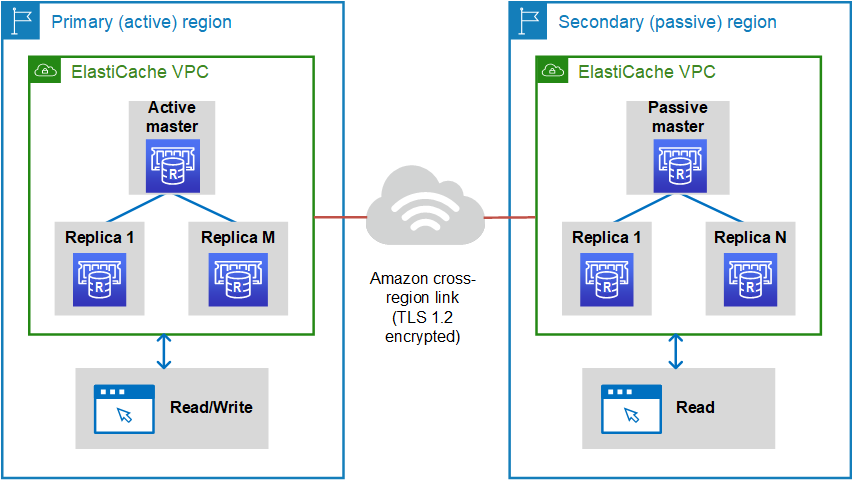{kind=link}